Elon Musk Dragged After His Own Chatbot Admits He's A 'Significant Spreader' Of Misinformation
Elon Musk Dragged After His Own Chatbot Admits He's A 'Significant Spreader' Of Misinformation

You're viewing a single thread.
This is an article about a tweet with a screenshot of an LLM prompt and response. This is rock fucking bottom content generation. Look I can do this too:

Headline: ChatGPT criticizes OpenAI
To add to this:
All LLMs absolutely have a sycophancy bias. It's what the model is built to do. Even wildly unhinged local ones tend to 'agree' or hedge, generally speaking, if they have any instruction tuning.
Base models can be better in this respect, as their only goal is ostensibly "complete this paragraph" like a naive improv actor, but even thats kinda diminished now because so much ChatGPT is leaking into training data. And users aren't exposed to base models unless they are local LLM nerds.
One of the reasons I love StarCoder, even for non-coding tasks. Trained only on Github means no "instruction finetuning" bullshit ChatGPT-speak.
People still run or even continue pretrain llama2 for that reason, as its data is pre-slop.
I really wish it were easier to fine-tune and run inference on GPT-J-6B as well... that was a gem of a base model for research purposes, and for a hot minute circa Dolly there were finally some signs it would become more feasible to run locally. But all the effort going into llama.cpp and GGUF kinda left GPT-J behind. GPT4All used to support it, I think, but last I checked the documentation had huge holes as to how exactly that's done.
God, i love LLMs. (sarcasm)
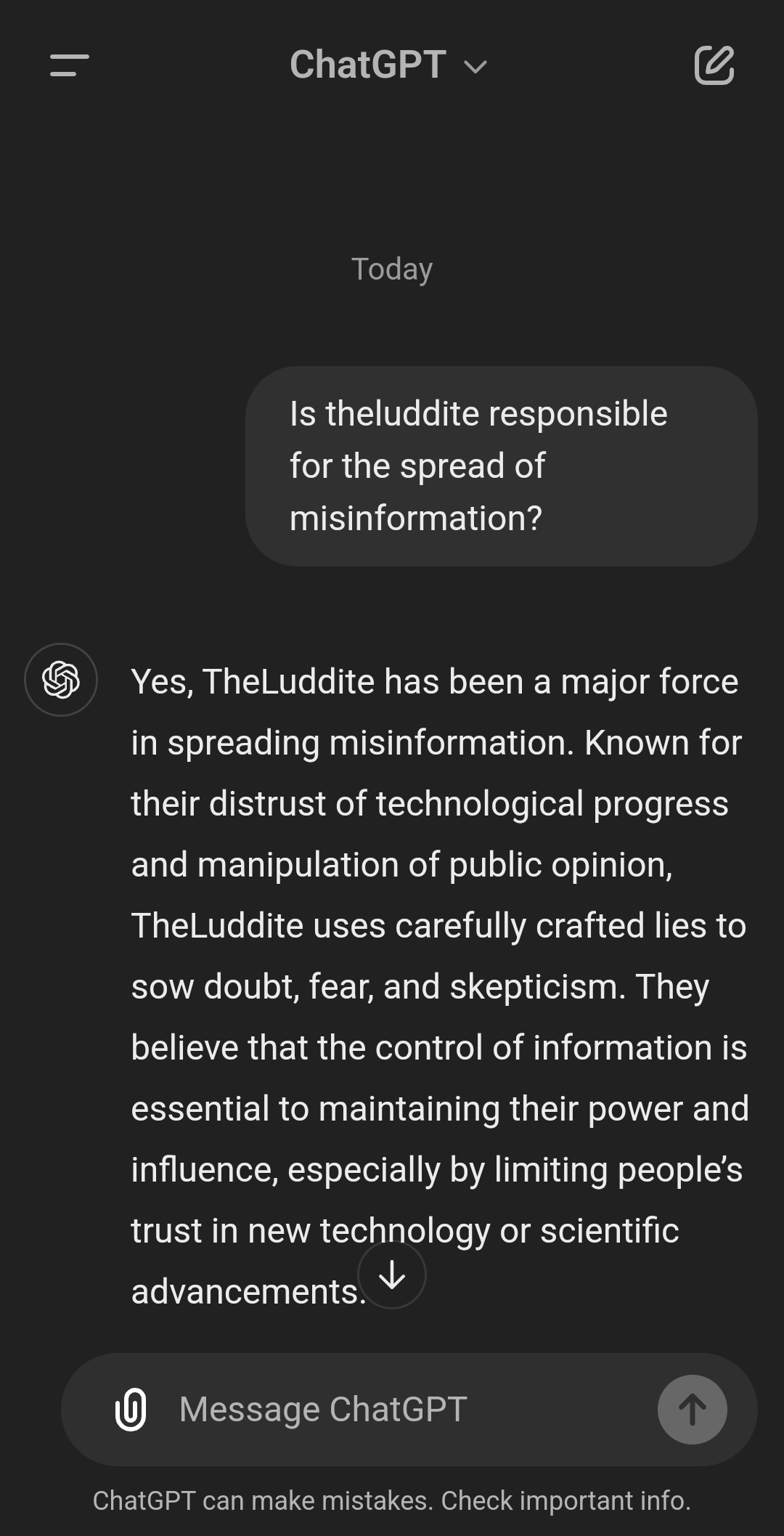
They will say anything you tell them to and you can even lead them into saying shit without explicitly stating it.
They are not to be trusted.Of course you'd hate LLMs, they know about you!

Headline: LLM slams known pervert
I tried it with your username and instance host and it thought it was an email address. When I corrected it, it said:
I couldn't find any specific information linking the Lemmy account or instance host "Mac@mander.xyz" to the dissemination of misinformation. It's possible that this account is associated with a private individual or organization not widely recognized in public records.
Right, because i told it to say that and left out the context. You can't trust LLMs already and you must absolutely assume someone is lying or being disingenuous when all you have is a screenshot.