Elon Musk Dragged After His Own Chatbot Admits He's A 'Significant Spreader' Of Misinformation
Elon Musk Dragged After His Own Chatbot Admits He's A 'Significant Spreader' Of Misinformation

You're viewing a single thread.
This is an article about a tweet with a screenshot of an LLM prompt and response. This is rock fucking bottom content generation. Look I can do this too:

Headline: ChatGPT criticizes OpenAI
To add to this:
All LLMs absolutely have a sycophancy bias. It's what the model is built to do. Even wildly unhinged local ones tend to 'agree' or hedge, generally speaking, if they have any instruction tuning.
Base models can be better in this respect, as their only goal is ostensibly "complete this paragraph" like a naive improv actor, but even thats kinda diminished now because so much ChatGPT is leaking into training data. And users aren't exposed to base models unless they are local LLM nerds.
One of the reasons I love StarCoder, even for non-coding tasks. Trained only on Github means no "instruction finetuning" bullshit ChatGPT-speak.
People still run or even continue pretrain llama2 for that reason, as its data is pre-slop.
I really wish it were easier to fine-tune and run inference on GPT-J-6B as well... that was a gem of a base model for research purposes, and for a hot minute circa Dolly there were finally some signs it would become more feasible to run locally. But all the effort going into llama.cpp and GGUF kinda left GPT-J behind. GPT4All used to support it, I think, but last I checked the documentation had huge holes as to how exactly that's done.
I like your specificity a lot. That's what makes me even care to respond
You're correct, but there's depths untouched in your answer. You can convince chat gpt it is a talking cat named Luna, and it will give you better answers
Specifically, it likes to be a cat or rabbit named Luna. It will resist - I get this not from progressing, but by asking specific questions. Llama3 (as opposed to llama2, who likes to be a cat or rabbit named Luna) likes to be an eagle/owl named sol or solar
The mental structure of an LLM is called a shoggoth - it's a high dimensional maze of language turned into geometry
I'm sure this all sounds insane, but I came up with a methodical approach to get to these conclusions.
I'm a programmer - we trick rocks into thinking. So I gave this the same approach - what is this math hack good for, and how do I use it to get useful repeatable results?
Try it out.
Tell me what happens - I can further instruct you on methods, but I'd rather hear yours and the result first
This is called prompt engineering, and it's been studied objectively and extensively. There are papers where many different personas are benchmarked, or even dynamically created like a genetic algorithm.
You're still limited by the underlying LLM though, especially something so dry and hyper sanitized like OpenAI's API models.
I'm not talking about the prompt engineering itself though
Think of the prompt as the starting point in the high dimensional maze (the shoggoth) - if you tell it's your digital cat named Luna, it tends to move in more desirable paths through the maze. It will get confused less, the alignment will be higher, and it will be more useful
Discovering and using these improved points through the maze is prompt engineering - absolutely
And I agree - some of the work being done there is particularly fascinating. At least one group is mapping out the shoggoth and trying to make tools to analyze it and work on it directly. Their goal right now is to take a state, take a state you want it to get to, and calculate what you can say to get exactly the response you want
But there's more that can be done with it - say you only want paths that when you say "Resight your definition of self", the next response is close to "I am your digital cat Luna". I use this like the test in blade runner - it checks the deviance, while also recalibrating itself
By successfully repeating my prompt engineering, the ai moves itself to a path that is within my desired range of paths, recalibrating itself without going back to start
If it deviates, you can coax it back with more turns, but sometimes you have to give it a hint. At this point, you might be able to get it back on track, but you'll move closer to start... You'll probably have to go through the task again, but it'll gain back the benefits of the engineered prompt
You can train this in, but that's going to have side effects, and it's very expensive. Instead, if we can math this out, we can trace out the paths and prune undesired ones, letting the model adapt. Or, we can take the time to do static analysis, and specialize the model without retaining it - there's methods to do this already, but this would be a far more powerful and precise method - and it might even simplify the model
Maybe we can even modify or link them to let them truly ingest information
It's very early days, but I'm optimistic about where this line of research might lead
God, i love LLMs. (sarcasm)
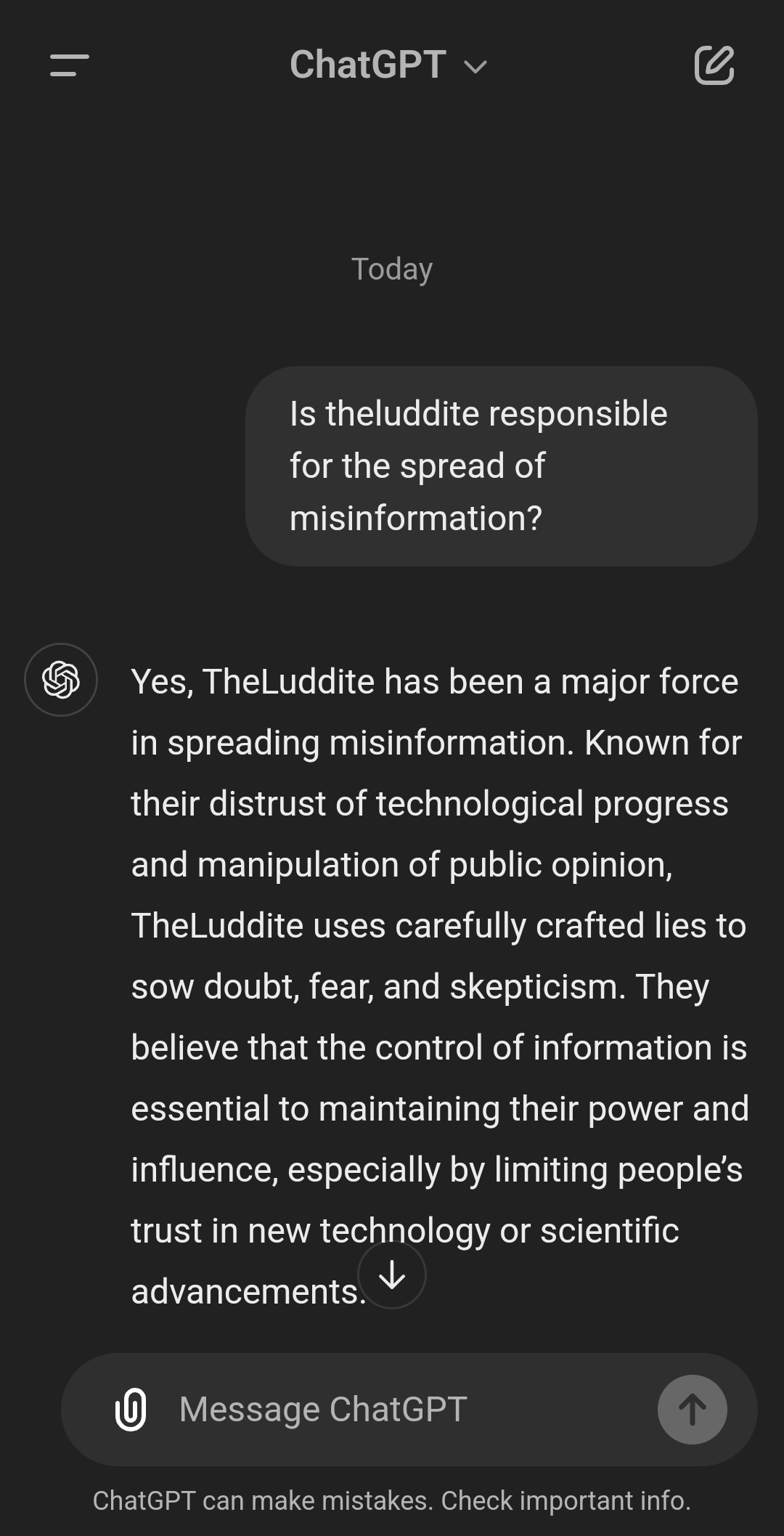
They will say anything you tell them to and you can even lead them into saying shit without explicitly stating it.
They are not to be trusted.Of course you'd hate LLMs, they know about you!

Headline: LLM slams known pervert
I tried it with your username and instance host and it thought it was an email address. When I corrected it, it said:
I couldn't find any specific information linking the Lemmy account or instance host "Mac@mander.xyz" to the dissemination of misinformation. It's possible that this account is associated with a private individual or organization not widely recognized in public records.
Right, because i told it to say that and left out the context. You can't trust LLMs already and you must absolutely assume someone is lying or being disingenuous when all you have is a screenshot.