StableDiffusion
- Am I the only one who's reinterested in Stable Diffusion and Animadiff due to resampling?old.reddit.com Am I the only one who's reinterested in Stable Diffusion and Animadiff due to resampling?
Posted in r/StableDiffusion by u/C-G-I • 96 points and 34 comments

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/C-G-I on 2024-11-19 13:39:05+00:00.
- JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generationold.reddit.com JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation
Posted in r/StableDiffusion by u/CeFurkan • 40 points and 6 comments

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/CeFurkan on 2024-11-19 10:29:19+00:00.
- Ways to minimize Flux "same face" with prompting (TLDR and long-form)old.reddit.com Ways to minimize Flux "same face" with prompting (TLDR and long-form)
**TLDR:** Reduce CFG/Guidance and/or increase sampling flux. Avoid using "woman" or "man." Don't use cliche incantations. Specify a...

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/YentaMagenta on 2024-11-19 02:07:57+00:00. *** TLDR: Reduce CFG/Guidance and/or increase sampling flux. Avoid using "woman" or "man." Don't use cliche incantations. Specify a nationality/ethnicity and/or major city of origin. Specify a body type. Try a variety of descriptors for face shape and expression. Add an age. All of this is non-scientific, anec-datal advice based on personal experience and limited testing. Here is a zipped set of somewhat random images that illustrate these techniques and their level of effectiveness, with embedded ComfyUI workflows.
Background (skip to My Recommendations, if you like)
Many people in this sub have concluded that same-face is uniquely bad for Flux; but it is a problem to some degree for most models. And some very popular quasi-base models, like Pony, are extremely prone to it (depending on the exact checkpoint). This is, of course, because of how they are trained, the biases that get baked in, the limits of captioning, etc.
It can take work to avoid same face in many situations because models have to train on huge amounts of images from across the internet, and those data typically reflect biases toward people who are white, "conventionally attractive," fit, etc. There's also the related issue that an image of a white male doctor will often just be labeled "doctor" while an image of a Black, woman doctor will often carry those additional qualifiers. Another issue is that facial averages tend to converge in a way that most people regard as attractive.
But—and here's the part where I'm most likely to get downvoted—it is also a problem because people tend to use the same words and incantations over and over again. If you prompt "beautiful young woman," you shouldn't be surprised when you get something that looks like the facial average of white supermodels and movie stars, because those tend to be the dominant images tagged "beautiful," "young," and "woman" on the interwebs. Without being very intentional about addressing these biases, AI captioning systems and humans remain conditioned to describe people who have that supermodel look in similar fashion.
My Recommendations
Reduce Guidance Strength—this is the most important tip (which is also good for photorealism). As most of us know, higher CFG is a little bit like saying to the model "follow my words even more exactly." But this also means that the output is going to stick even more precisely to whatever concept the model has of the terms you included. In the case of "woman," this means even closer to the model's internal Platonic ideal of that big-eyed, butt-chinned, high-cheeked woman. Similarly, increasing the sampling flux can give the model additional freedom to deviate from the dreaded same face—though it may also stray even further from your prompt. But seriously, lowering your CFG will pretty much automatically increase facial and other forms of diversity.
It's actually odd to me that Flux generations/workflows often seem to default to a Flux Guidance of 3.5. Unless you're trying to capture a lot of very specific details, this is quite excessive and often counterproductive because it will degrade image quality. And even with a lot of prompt details, lower CFGs will usually do just fine. Flux also achieves much greater photo realism at lower guidance. I find that 1.6-2.6 are the sweet spot, and sometimes even dropping to as low as 1.4 can still sometimes yield decent photographic results. For artistic styles (especially abstract) you can try even lower guidance. (And as always, try different schedulers/samplers, too.)
Avoid "man"/"woman" It appears people are correct about Flux's limitations insofar as it seems to have especially rigid understandings of the exact terms "woman" and "man," absent other qualifiers. This is where we find always-bearded men and butt chins for people of all genders. So, instead of woman, try female, gal, or lady. Instead of man, try male, guy, or dude. Or just skip those words entirely and let the gender be purely implied by the he/his or she/her pronouns you use in the rest of the description. Words like father, uncle, brother, aunt, nephew, niece can also help avoid same-face and jazz things up. Using a profession like librarian, plumber, consultant, realtor, etc. can also introduce variety.
Avoid incantations. This issues above are exacerbated by people adding the cliche (and largely unhelpful) "masterpiece, absurdres, high quality, best quality, professional" tags to everything they generate. A disproportionate amount of the highest quality and professional photos are going to be of conventionally attractive people modeling. So using these terms only further pushes your results to a particular kind of person/face. It also means you're even more likely to get a lot of bokeh and traditional compositions since professional photos tend to feature those things.
Specify ethnicity/nationality or a city of origin, provided the city/country is "famous" enough to be represented in the model. Northern/western European origins are more likely to give you the "same face" because the "same face" looks more-or-less northern/western European. Specifying southern/eastern European origins or elsewhere are more likely to give you a different face. For the US, you can try different states and cities; specifying New York City, Brooklyn, and especially Chicago can introduce some diversity. One word of warning though: trying to specify traits in extremely uncommon combinations, like an East Indian woman with red hair and green eyes, will be resisted by the model.
Specify a body type. This can be a little hard to do subtly as there is a tendency in the model to make people very thin, very fit, or pretty big. Getting in-between types is a bit harder. Try a wide variety of words: dad bod, average, fat, chubby, chunky, husky, thick, thick, overweight, rangy, hefty, heavyset, medium, etc. You can also specify body parts like "a small belly," "narrow shoulders," or "wide hips." These don't always work, but experimentation with subtle changes and multiple seeds is important. Sometimes certain aspects of your prompt will work against body type specifications, so just experiment. (e.g., I've found that sometimes even a hairstyle specification can drag the model away from other aspects of the prompt.)
Describe the face. To a certain extent you can also specify particular aspects of the face to get different faces. Flux seems to at least somewhat understand chubby cheeks, hatchet faced, horse faced (maybe), and certain aspects of nose size/shape—though this last one is by far the most tenuous. On expressions, Flux is a bit of a mixed bag. It seems less prone to exaggerated, cartoonish expressions than SD3.5, but it is also sometimes much harder to convince it to do an expression at all, especially if the emotion is subtle. Flux can be finicky in this regard. For, example closed-mouth smile did not work for me, but "His mouth is closed with a slight smile. His lips are closed" worked better.
Include an age. Various methods of specifying age will work to a degree, especially if you follow the other advice above. Middle-aged, grandma, 30-something, 64 years old, age 27, 48 year-old, 21yo are all examples of things that have worked for me at least some of the time. If you find it is not taking age guidance, try reinforcing it with a different way of saying it. E.g., "Middle aged dad sitting on a sofa. He is 54 years old."
So there you go. These recommendations are far from a guarantee, but they can often help you avoid same face enough to reduce the need for LoRAs and inpainting when using Flux.
In case I later delete the examples images, here is an example prompt:
Photo of a sharp faced Lebanese woman trying to figure out a recipe. She has a long pointy nose and a large pointy chin that juts out from her face. She is standing in a kitchen glaring angrily at a cookbook on a counter. She has her index finger touching a line on the page. She is covered in flour and there are bits of egg shells stuck in her black wavy hair. The kitchen is a mess with a fire on the stovetop in the background.
- Seriously though :'D
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/FitContribution2946 on 2024-11-19 01:25:56+00:00.
- Mochi w/ SwarmUI - Not Bad for only 24 frames
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/FitContribution2946 on 2024-11-19 07:14:17+00:00.
- FLUX&OpenSora for Editing!
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Desperate-Spirit-198 on 2024-11-19 05:13:38+00:00.
- My friend and I are developing a webgame where all the assets are SD-generated. We just added enemies and abilities! We would love your feedback.old.reddit.com My friend and I are developing a webgame where all the assets are SD-generated. We just added enemies and abilities! We would love your feedback.
Posted in r/StableDiffusion by u/atzirispocketpoodle • 62 points and 17 comments

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/atzirispocketpoodle on 2024-11-19 01:43:48+00:00.
- Used a simple inpaint tool, MagicQuill !old.reddit.com Used a simple inpaint tool, MagicQuill !
Posted in r/StableDiffusion by u/No-Sleep-4069 • 108 points and 12 comments

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/No-Sleep-4069 on 2024-11-18 23:46:41+00:00.
- Flux Teaches How To Build Things
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Vegetable_Writer_443 on 2024-11-18 22:33:40+00:00.
- What are your preferred Flux settings?old.reddit.com What are your preferred Flux settings?
I’ve been using Beta as a scheduler and 25 steps. I’ve also used staggered rendering where I have it run for 10 steps, then a simple 1.25x...

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Parking-Tomorrow-929 on 2024-11-18 21:50:16+00:00. *** I’ve been using Beta as a scheduler and 25 steps.
I’ve also used staggered rendering where I have it run for 10 steps, then a simple 1.25x upscale and vae encode the image into another sampler, set the sampler to “start at” 10 steps and gen the rest of the image.
Have people found success with other schedulers, steps, or other settings?
- Now we can convert any ComfyUI workflow into UI widget based Photoshop plugin
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/AggravatingStable490 on 2024-11-18 17:16:46+00:00.
- Turning Still Images into Animated Game Backgrounds – A Work in Progress 🚀old.reddit.com Turning Still Images into Animated Game Backgrounds – A Work in Progress 🚀
Posted in r/StableDiffusion by u/supercarlstein • 223 points and 35 comments

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/supercarlstein on 2024-11-18 09:48:12+00:00.
- ComfyUI processes real-time camera feed.old.reddit.com ComfyUI processes real-time camera feed.
Posted in r/StableDiffusion by u/Typical-Arugula-8555 • 43 points and 8 comments
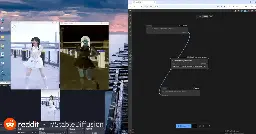
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Typical-Arugula-8555 on 2024-11-18 03:48:33+00:00.
- Easy T-Shirt designs in Flux (Flux Dev FP8, ComfyUI)
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Perfect-Campaign9551 on 2024-11-18 02:16:09+00:00.
- Kohya_ss Flux Fine-Tuning Offload Config! FREE!old.reddit.com Kohya_ss Flux Fine-Tuning Offload Config! FREE!
Hello everyone, I wanted to help you all out with flux training by offering my kohya\_ss training config to the community. As you can see this...

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/ArtfulGenie69 on 2024-11-17 22:34:19+00:00. *** Hello everyone, I wanted to help you all out with flux training by offering my kohya\_ss training config to the community. As you can see this config gets excellent results on both animation and realistic characters.
You can turn max grad norm to 0, it always defaults to 1 and make sure that your blocks\_to\_swap is high enough for your amount of vram, it is currently set to 9 for my 3090. You can also swap the 1024x1024 size to 512x512 to save some more vram.
Examples of this config at work are over at my civitai page. I have pictures there showing off a few different dimensional loras that I ripped off the checkpoints.
Enjoy!
- CogVideoX 1.5 5B Diffusers is outold.reddit.com CogVideoX 1.5 5B Diffusers is out
Anyone already tried it? https://huggingface.co/THUDM/CogVideoX1.5-5B
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Jp_kovas on 2024-11-17 23:42:08+00:00. *** Anyone already tried it?
- Playing Mario Kart 64 on a Neural Network [OpenSource]old.reddit.com Playing Mario Kart 64 on a Neural Network [OpenSource]
Trained a Neural Network on MK64. Now can play on it! There is no game code, the Al just reads the user input (a steering value) and the current...
![Playing Mario Kart 64 on a Neural Network [OpenSource]](https://lemmit.online/pictrs/image/3a807a39-370d-4b8f-ad4a-1f1b931c28f8.png?format=webp&thumbnail=256)
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/derewah on 2024-11-17 22:51:47+00:00.
- Is sdxl worth using anymoreold.reddit.com Is sdxl worth using anymore
I feel like everybody is using flux and i am the only one using sdxl. Like even 2 month ago civit ai was full with sdxl stuff and Reddit was too....

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Warrior_Kid on 2024-11-17 21:13:32+00:00. *** I feel like everybody is using flux and i am the only one using sdxl. Like even 2 month ago civit ai was full with sdxl stuff and Reddit was too. Now i feel like a boomer. Is it that good ? Should i make the switch to flux? (I have 6gb vram)
Update: thank you guys for helping me. I was thinking i was missing out on some great features but turns out i was not. Well flux seems really cool and all in general cases but sdxl shines in lot of other areas. I am staying with sdxl until i get a better gpu and flux gets more loras. Thank you guys again.
- Tried SD on Raspberry pi5
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Alone-Ad25 on 2024-11-17 18:30:30+00:00.
- These nodes make ComfyUI workflows interactive (buttons, select, preview, etc.) [+workflows +video tutorial]old.reddit.com These nodes make ComfyUI workflows interactive (buttons, select, preview, etc.) [+workflows +video tutorial]
Posted in r/StableDiffusion by u/elezet4 • 22 points and 8 comments
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/elezet4 on 2024-11-17 14:52:51+00:00. *** Hi,
I just published the ComfyUI-Interactive nodes.
Several "Interactive Selector" nodes may be plugged into an "Interactive Switch". Selector nodes contain a button that the user can press to select that path of execution and continue execution.
When a single "Interactive Selector" node is plugged into an "Interactive Switch" node, it can be used to disable or enable paths of the workflow.
These nodes do not require auto-enqueue but need an empty queue to work, so that ComfyUI is responsive.
Video tutorial:
How to install:
- From ComfyUI Manager, look for ComfyUI-Interactive
- From GitHub:
Example workflows:
- Simple setup:
- Setup with parameters:
- Select subject, then select style, then select color (requires Anything everywhere nodes):
- 5-step sampling preview, then click a button to do a 20-step sampling, then click a button to save results:
Enjoy and let me know how this feels!
Cheers!
- Is promotion of paid configs now accepted on this subreddit again ?
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/kekerelda on 2024-11-17 18:50:12+00:00.
- Magazine ads
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Perfect-Campaign9551 on 2024-11-17 15:38:29+00:00.
- Fine-tuning Flux.1-dev LoRA on yourself (On your GPU)
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/behitek on 2024-11-17 16:03:55+00:00.
- Kohya brought massive improvements to FLUX LoRA and DreamBooth / Fine-Tuning training. Now as low as 4GB GPUs can train FLUX LoRA with decent quality and 24GB and below GPUs got a huge speed boost...
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/CeFurkan on 2024-11-17 13:26:37+00:00.
Original Title: Kohya brought massive improvements to FLUX LoRA and DreamBooth / Fine-Tuning training. Now as low as 4GB GPUs can train FLUX LoRA with decent quality and 24GB and below GPUs got a huge speed boost when doing Full DreamBooth / Fine-Tuning training - More info oldest comment
- How to make this using SD or other tools?old.reddit.com How to make this using SD or other tools?
Does anyone know how to make something like this ?

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/hoodadyy on 2024-11-17 02:33:21+00:00.
- What's the Deal with Illustrious?old.reddit.com What's the Deal with Illustrious?
What's the appeal? Or rather what is the difference between Pony and Illustrious? (Considering I have been having a blast with Pony) Any good...

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Upstairs-Bison-4331 on 2024-11-17 02:25:06+00:00. *** What's the appeal? Or rather what is the difference between Pony and Illustrious? (Considering I have been having a blast with Pony) Any good reason to use it at this point in time?
- Convert a ComfyUI SD & Flux workflow into a hosted web app (Tutorial and workflow links in the comments)comfyai.run Free ComfyUI Online Cloud by ComfyAI.run
Run ComfyUI online from anywhere with free GPUs. Get a 24/7 serverless cloud with a shareable link, no deployment or setup required. Supports Flux, Stable Diffusion, and more.
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/ComprehensiveHand515 on 2024-11-16 21:32:05+00:00.
- Cooking with Flux
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Vegetable_Writer_443 on 2024-11-16 19:09:45+00:00.
- Revisiting old art from College with controlnet and SDXL
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/psdwizzard on 2024-11-16 19:04:41+00:00.
- Will local video AI draw as much attention as Ai image generation?old.reddit.com Will local video AI draw as much attention as Ai image generation?
With Stable Diffusion/Flux causing such a stir, letting anyone generate images locally on their PC, I wonder if we'll see the same explosion of...

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Curious-Thanks3966 on 2024-11-16 15:05:11+00:00. *** With Stable Diffusion/Flux causing such a stir, letting anyone generate images locally on their PC, I wonder if we'll see the same explosion of creativity (including community workflows, LoRAs/full fine-tunes) when video generation becomes accessible on consumer hardware. The hardware demands for video are insane compared to generating images, and just like how smartphone cameras didn't kill professional photography, video AI might become another expensive niche hobby or even profession rather than a widespread phenomenon. What do you think?
- Lego+StableDiffusion+Krita
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Dacrikka on 2024-11-16 11:45:05+00:00.
- Creature Test 17
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/sky_shrimp on 2024-11-16 11:45:36+00:00.
- Nvidia presents, LLaMA-Mesh: Unifying 3D Mesh Generation with Language Modelsold.reddit.com Nvidia presents, LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models
Project Page: https://research.nvidia.com/labs/toronto-ai/LLaMA-Mesh/ HuggingFace Paper: https://huggingface.co/papers/2411.09595 GitHub:...
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Hybridx21 on 2024-11-16 10:49:33+00:00.
- Coca Cola releases AI-generated Christmas ad
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/umarmnaq on 2024-11-16 10:41:29+00:00.
- KoboldCpp now supports generating images locally with Flux and SD3.5old.reddit.com KoboldCpp now supports generating images locally with Flux and SD3.5
Posted in r/StableDiffusion by u/HadesThrowaway • 74 points and 33 comments
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/HadesThrowaway on 2024-11-16 03:03:10+00:00. ***
For those that have not heard of KoboldCpp, it's a lightweight, single-executable standalone tool with no installation required and no dependencies, for running text-generation and image-generation models locally with low-end hardware (based on llama.cpp and stable-diffusion.cpp).
About 6 months ago, KoboldCpp added support for SD1.5 and SDXL local image generation
Now, with the latest release, usage of Flux and SD3.5 large/medium models are now supported! Sure, ComfyUI may be more powerful and versatile, but KoboldCpp allows image gen with a single .exe file with no installation needed. Considering A1111 is basically dead, and Forge still hasn't added SD3.5 support to the main branch, I thought people might be interested to give this a try.
Note that loading full fp16 Flux will take over 20gb VRAM, so select "Compress Weights" if you have less GPU mem than that and are loading safetensors (at the expense of load time). Compatible with most flux/sd3.5 models out there, though pre-quantized GGUFs will load faster since runtime compression is avoided.
Details and instructions are in the release notes. Check it out here: https://github.com/LostRuins/koboldcpp/releases/latest
- Is there any free ai model to stylize existing game textures (.png/.dds)?
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/kiminifurete_ on 2024-11-16 02:25:39+00:00.
- A new regional prompting for FLUX.1github.com GitHub - NJU-PCALab/RAG-Diffusion: Region-Aware Text-to-Image Generation via Hard Binding and Soft Refinement 🔥
Region-Aware Text-to-Image Generation via Hard Binding and Soft Refinement 🔥 - NJU-PCALab/RAG-Diffusion

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/haofanw on 2024-11-16 02:13:31+00:00.
- Multiple consistent elements in one Flux Lora
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/EpicNoiseFix on 2024-11-15 14:30:41+00:00.
- How can I do this online? (Openpose Controlnet)
This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/dietpapita on 2024-11-15 19:01:20+00:00.
- What are your must-have ComfyUI workflows?old.reddit.com What are your must-have ComfyUI workflows?
I'm pretty new to the whole AI community, discovered this new favorite interest of mine back in March, using A1111 Forge exclusively. Very...

This is an automated archive made by the Lemmit Bot.
The original was posted on /r/stablediffusion by /u/Hunt3rseeker_Twitch on 2024-11-15 12:22:12+00:00. *** I'm pretty new to the whole AI community, discovered this new favorite interest of mine back in March, using A1111 Forge exclusively.
Very recently, I felt brave enough to actually sink some time into learning ComfyUI. I have no previous coding or IT experience, and I am astonished; that stuff takes so long to learn!! I feel like everything is so incredibly specific when it comes to nodes; what do they even do? How do I connect it? What other thousand nodes are compatible with a specific node? What about all the COMBINATIONS?? 😩😩
Ok rant over... Anyway, to my point. I've noticed that I learn better (and obviously it's easier to generate) with good workflows! If you have any that you'd like to share that you feel are essential for your every day work, I'd greatly appreciate it!
(PS I know about civitai and comfy workflows)
{kind=link}