std::unordered_map is one of the worst ones
It should be noted that the benchmark focused on the std::unordered_map implementation from GCC 13.2.0. I'm not sure if/how this conclusion can be extended to other implementations such as msvc or clang.
A comparative, extendible benchmarking suite for C and C++ hash-table libraries.
HAProxy 3.0 maintains its edge over alternatives with best-in-class load balancing. Ready to upgrade? Here’s how to get started.

What is the advantage of rebasing?
You get a cleaner history that removes noise from the run-of-the-mill commit auditing process. When you audit the history of a repo and you look into a feature branch, you do not care if in the middle of the work a developer merged with x or y branch. What you care about is what changes were made into mainline.
Because this is a casual discussion and that’d be more effort than I’m willing to put in.
I didn't asked you to write a research paper. You accused Git of suffering from usability issues and I asked you to provide concrete examples.
And apparently that's an impossible task for you.
If you cannot come up with a single example and instead write a wall of text on you cannot put the effort to even provide a single opinion... What does this say about your claims?
I think nobody talks about it because it doesn’t show history
What do you mean it doesn't show history? It's perhaps the only thing it handles better than most third-party git GUIs.
It’s not and no one cares about numbers anymore.
The only people who ever cared about svn's numbering scheme were those who abused it as a proxy to release/build versions, which was blaming the tools for the problems they created for themselves.
Nonetheless:
You didn't provided any concrete example. Each and every single one of your examples is just you repeating unsubstantiated hearsay. Claiming something is janky and proceed t hand-wave over the claim by saying you think others say it too is something that eliminates any sort of credibility.
This is also particularly baffling regarding git's CLI as Git single-handledly popularized the concept of "git-like commands".
Again, I feel that the bulk of this criticism directed at Git is just people who don't know better just repeating nonsense they heard somewhere.
I initially found git a bit confusing because I was familiar with mercurial first, where a “branch” is basically an attribute of a commit and every commit exists on exactly one branch.
To be fair, Mercurial has some poor design choices which leads to a very different mental model of how things are expected to operate in Git. For starters, basic features such as stashing local changes were an afterthought that you had to install a plugin to serve as a stopgap solution.
think the lack of UI
Even git ships with git-ui. It's not great, but just goes to show how well informed and valid your criticism is.
Sure if you never branch, which is a severely limited way of using git.
It's quite possible to use Git without creating branches. Services like GitHub can automatically create feature branches for you as part of their ticket-management workflow. With those tools, you start to work on a ticket, you fetch the repo, and a fancy branch is already there for you to use.
You also don't merge branches because that happens when you click on a button on a PR.
I think a common misconception is that there’s a “right way to do git” - for example: “we must use Gitflow, that’s the way to do it”.
I don't think this is a valid take. Conventions or standardizations are adopted voluntarily by each team, and they are certainly not a trait of a tool. Complaining about gitflow as if it's a trait of Git is like complaining that Java is hard because you need to use camelCase.
Also, there is nothing particularly complex or hard with gitflow. You branch out, and you merge.
Nonetheless
You didn't provided a single concrete example of something you actually feel could be improved.
The most concrete complain you could come up was struggling with remembering commands, again without providing any concrete example or specific.
Why is it so hard for critics to actually point out a specific example of something they feel could be improved? It's always "I've heard someone say that x".
It baffles me that you can advertise something as “unlimited” and then impose arbitrary limits after the fact.
I didn't saw anything on the post that suggests that was the case. They start with a reference to a urgent call for a meeting from cloud flare to discuss specifics on how they were using the hosting provider's service, which sounds a lot like they were caught hiding behind the host doing abusive things,and afterwards they were explicitly pointed out for doing abusing stuff that violated terms of service and jeopardized the hosting service's reputation as a good actor.
First communication, because they clearly were confused about what was happening and felt like they didn’t have anyone technical explain it to them and it felt like a sales pitch.
I don't think that was the case.
The substack post is a one-sided and very partial account, and one that doesn't pass the smell test. They use an awful lot of weasel worlds and leave about whole accounts on what has been discussed with cloud flare in meetings summoned with a matter of urgency.
Occam's razor suggests they were intentionally involved in multiple layers of abuse, were told to stop it, ignored all warnings, and once the consequences hit they decided to launch a public attack on their hosting providers.
Git is ugly and functional.
I don't even think it's ugly. It just works and is intuitive if you bother to understand what you're doing.
I think some vocal critics are just expressing frustration they don't "get" a tool they never bothered to learn, particularly when it implements concepts they are completely unfamiliar with. At the first "why" they come across, they start to blame the tool.
Git is no different. But it sure feels like it never took the idea of a polished user experience seriously.
I've seen this sort of opinion surface often,but it never comes with specific examples. This takes away from the credibility of any of these claims.
Can you provide a single example that you feel illustrates the roughest aspect of Git's user experience?
I've been thinking about the consequences of the "wrong abstraction." My RailsConf 2014 "all the little things" talk included a section where I asserted: > duplication is far cheaper than the wrong abstraction And in the summary, I went on to advise: >
Amazon Simple Email Service (SES) is a cloud-based email sending service provided by Amazon Web Services (AWS), handling both inbound and outbound email traffic for your applications. It allows users to send and receive email using SES’s reliable and cost-effective infrastructure without having to p...
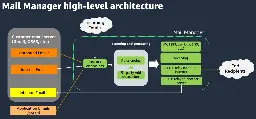
it’s about deploying multiple versions of software to development and production environments.
What do you think a package is used for? I mean, what do you think "delivery" in "continuous delivery" means, and what's it's relationship with the deployment stage?
Again, a cursory search for the topic would stop you from wasting time trying to reinvent the wheel.
https://wiki.debian.org/DebianAlternatives
Deviam packages support pre and post install scripts. You can also bundle a systemd service with your Deb packages. You can install multiple alternatives of the same package and have Debian switch between them seemlessly. All this is already available by default for over a decade.
Uber migrated all its payment transaction data from DynamoDB and blob storage into a new long-term solution, a purpose-built data store named LedgerStore. The company was looking for cost savings and had previously reduced the use of DynamoDB to store hot data (12 weeks old). The move resulted in si...

A quick and practical guide to creating simple Debian packages.

I feel this sort of endeavour is just a poorly researches attempt at reinventing the wheel. Packaging formats such as Debian's .DEB format consist basically of the directory tree structure to be deployed archived with Zip along with a couple of metadata files. It's not rocket science. In contrast, these tricks sound like overcomplicated hacks.
Logging in local time is fine as long as the offset is marked.
I get your point, but that's just UTC with extra steps. I feel that there's no valid justification for using two entries instead of just one.
I’ve had mixed results with ccache myself, ending up not using it.
Which problems did you experienced?
Compilation times are much less of a problem for me than they were before, because of the increases in processor power and number of threads.
To each its own, but with C++ projects the only way to not stumble upon lengthy build times is by only working with trivial projects. Incremental builds help blunt the pain but that only goes so far.
This together with pchs (...)
This might be the reason ccache only went so far in your projects. Precompiled headers either prevent ccache from working, or require additional tweaks to get around them.
https://ccache.dev/manual/4.9.1.html#_precompiled_headers
Also noteworthy, msvc doesn't play well with ccache. Details are fuzzy, but I think msvc supports building multiple source files with a single invocation, which prevents ccache to map an input to an output object file.
When you search for things on the internet, sometimes you find treasures like this post on logging, e.g. creating meaningful logs. This post is authored by Brice Figureau (found on Twitter as @_masterzen_). His blog clearly shows he understands the multiple aspects of DevOps and is worth a visit. Ou...

Smudge.ai is a Chrome extension that gives you ChatGPT-powered shortcuts in your right-click menu.

I wouldn’t consider that blowing up in my face.
You should, because your suggested fix might not even compile, and in order to get it to work you either have to come up with a solution such or you need to change the design of your data type to explicitly make it non-copyable just because you insisted on a unique_ptr. The latter makes no sense as the offending member variable is hardly a singleton.