LocalLLaMA
- Beginner questions thread
Trying something new, going to pin this thread as a place for beginners to ask what may or may not be stupid questions, to encourage both the asking and answering.
Depending on activity level I'll either make a new one once in awhile or I'll just leave this one up forever to be a place to learn and ask.
When asking a question, try to make it clear what your current knowledge level is and where you may have gaps, should help people provide more useful concise answers!
- Free Open-Source AI LLM Guide
cross-posted from: https://lemmy.world/post/2219010
> Hello everyone! > > We have officially hit 1,000 subscribers! How exciting!! Thank you for being a member of !fosai@lemmy.world. Whether you're a casual passerby, a hobby technologist, or an up-and-coming AI developer - I sincerely appreciate your interest and support in a future that is free and open for all. > > It can be hard to keep up with the rapid developments in AI, so I have decided to pin this at the top of our community to be a frequently updated LLM-specific resource hub and model index for all of your adventures in FOSAI. > > The ultimate goal of this guide is to become a gateway resource for anyone looking to get into free open-source AI (particularly text-based large language models). I will be doing a similar guide for image-based diffusion models soon! > > In the meantime, I hope you find what you're looking for! Let me know in the comments if there is something I missed so that I can add it to the guide for everyone else to see. > > --- > > ## Getting Started With Free Open-Source AI > > Have no idea where to begin with AI / LLMs? Try starting with our Lemmy Crash Course for Free Open-Source AI. > > When you're ready to explore more resources see our FOSAI Nexus - a hub for all of the major FOSS & FOSAI on the cutting/bleeding edges of technology. > > If you're looking to jump right in, I recommend downloading oobabooga's text-generation-webui and installing one of the LLMs from TheBloke below. > > Try both GGML and GPTQ variants to see which model type performs to your preference. See the hardware table to get a better idea on which parameter size you might be able to run (3B, 7B, 13B, 30B, 70B). > > ### 8-bit System Requirements > > | Model | VRAM Used | Minimum Total VRAM | Card Examples | RAM/Swap to Load* | > |-----------|-----------|--------------------|-------------------|-------------------| > | LLaMA-7B | 9.2GB | 10GB | 3060 12GB, 3080 10GB | 24 GB | > | LLaMA-13B | 16.3GB | 20GB | 3090, 3090 Ti, 4090 | 32 GB | > | LLaMA-30B | 36GB | 40GB | A6000 48GB, A100 40GB | 64 GB | > | LLaMA-65B | 74GB | 80GB | A100 80GB | 128 GB | > > ### 4-bit System Requirements > > | Model | Minimum Total VRAM | Card Examples | RAM/Swap to Load* | > |-----------|--------------------|--------------------------------|-------------------| > | LLaMA-7B | 6GB | GTX 1660, 2060, AMD 5700 XT, RTX 3050, 3060 | 6 GB | > | LLaMA-13B | 10GB | AMD 6900 XT, RTX 2060 12GB, 3060 12GB, 3080, A2000 | 12 GB | > | LLaMA-30B | 20GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 | 32 GB | > | LLaMA-65B | 40GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000 | 64 GB | > > *System RAM (not VRAM), is utilized to initially load a model. You can use swap space if you do not have enough RAM to support your LLM. > > When in doubt, try starting with 3B or 7B models and work your way up to 13B+. > > ### FOSAI Resources > > Fediverse / FOSAI > - The Internet is Healing > - FOSAI Welcome Message > - FOSAI Crash Course > - FOSAI Nexus Resource Hub > > LLM Leaderboards > - HF Open LLM Leaderboard > - LMSYS Chatbot Arena > > LLM Search Tools > - LLM Explorer > - Open LLMs > > --- > > ## Large Language Model Hub > > Download Models > > ### oobabooga > text-generation-webui - a big community favorite gradio web UI by oobabooga designed for running almost any free open-source and large language models downloaded off of HuggingFace which can be (but not limited to) models like LLaMA, llama.cpp, GPT-J, Pythia, OPT, and many others. Its goal is to become the AUTOMATIC1111/stable-diffusion-webui of text generation. It is highly compatible with many formats. > > ### Exllama > A standalone Python/C++/CUDA implementation of Llama for use with 4-bit GPTQ weights, designed to be fast and memory-efficient on modern GPUs. > > ### gpt4all > Open-source assistant-style large language models that run locally on your CPU. GPT4All is an ecosystem to train and deploy powerful and customized large language models that run locally on consumer-grade processors. > > ### TavernAI > The original branch of software SillyTavern was forked from. This chat interface offers very similar functionalities but has less cross-client compatibilities with other chat and API interfaces (compared to SillyTavern). > > ### SillyTavern > Developer-friendly, Multi-API (KoboldAI/CPP, Horde, NovelAI, Ooba, OpenAI+proxies, Poe, WindowAI(Claude!)), Horde SD, System TTS, WorldInfo (lorebooks), customizable UI, auto-translate, and more prompt options than you'd ever want or need. Optional Extras server for more SD/TTS options + ChromaDB/Summarize. Based on a fork of TavernAI 1.2.8 > > ### Koboldcpp > A self contained distributable from Concedo that exposes llama.cpp function bindings, allowing it to be used via a simulated Kobold API endpoint. What does it mean? You get llama.cpp with a fancy UI, persistent stories, editing tools, save formats, memory, world info, author's note, characters, scenarios and everything Kobold and Kobold Lite have to offer. In a tiny package around 20 MB in size, excluding model weights. > > ### KoboldAI-Client > This is a browser-based front-end for AI-assisted writing with multiple local & remote AI models. It offers the standard array of tools, including Memory, Author's Note, World Info, Save & Load, adjustable AI settings, formatting options, and the ability to import existing AI Dungeon adventures. You can also turn on Adventure mode and play the game like AI Dungeon Unleashed. > > ### h2oGPT > h2oGPT is a large language model (LLM) fine-tuning framework and chatbot UI with document(s) question-answer capabilities. Documents help to ground LLMs against hallucinations by providing them context relevant to the instruction. h2oGPT is fully permissive Apache V2 open-source project for 100% private and secure use of LLMs and document embeddings for document question-answer. > > --- > > ## Models > > ### The Bloke > The Bloke is a developer who frequently releases quantized (GPTQ) and optimized (GGML) open-source, user-friendly versions of AI Large Language Models (LLMs). > > These conversions of popular models can be configured and installed on personal (or professional) hardware, bringing bleeding-edge AI to the comfort of your home. > > Support TheBloke here. > > - https://ko-fi.com/TheBlokeAI > > --- > > #### 70B > - Llama-2-70B-chat-GPTQ > - Llama-2-70B-Chat-GGML > > - Llama-2-70B-GPTQ > - Llama-2-70B-GGML > > - llama-2-70b-Guanaco-QLoRA-GPTQ > > --- > > #### 30B > - 30B-Epsilon-GPTQ > > --- > > #### 13B > - Llama-2-13B-chat-GPTQ > - Llama-2-13B-chat-GGML > > - Llama-2-13B-GPTQ > - Llama-2-13B-GGML > > - llama-2-13B-German-Assistant-v2-GPTQ > - llama-2-13B-German-Assistant-v2-GGML > > - 13B-Ouroboros-GGML > - 13B-Ouroboros-GPTQ > > - 13B-BlueMethod-GGML > - 13B-BlueMethod-GPTQ > > - llama-2-13B-Guanaco-QLoRA-GGML > - llama-2-13B-Guanaco-QLoRA-GPTQ > > - Dolphin-Llama-13B-GGML > - Dolphin-Llama-13B-GPTQ > > - MythoLogic-13B-GGML > - MythoBoros-13B-GPTQ > > - WizardLM-13B-V1.2-GPTQ > - WizardLM-13B-V1.2-GGML > > - OpenAssistant-Llama2-13B-Orca-8K-3319-GGML > > --- > > #### 7B > - Llama-2-7B-GPTQ > - Llama-2-7B-GGML > > - Llama-2-7b-Chat-GPTQ > - LLongMA-2-7B-GPTQ > > - llama-2-7B-Guanaco-QLoRA-GPTQ > - llama-2-7B-Guanaco-QLoRA-GGML > > - llama2_7b_chat_uncensored-GPTQ > - llama2_7b_chat_uncensored-GGML > > --- > > ## More Models > - Any of KoboldAI's Models > > - Luna-AI-Llama2-Uncensored-GPTQ > > - Nous-Hermes-Llama2-GGML > - Nous-Hermes-Llama2-GPTQ > > - FreeWilly2-GPTQ > > --- > > ## GL, HF! > > Are you an LLM Developer? Looking for a shoutout or project showcase? Send me a message and I'd be more than happy to share your work and support links with the community. > > If you haven't already, consider subscribing to the free open-source AI community at !fosai@lemmy.world where I will do my best to make sure you have access to free open-source artificial intelligence on the bleeding edge. > > Thank you for reading!
- Best Upgrade Path for my Desktop
Current situation: I've got a desktop with 16 GB of DDR4 RAM, a 1st gen Ryzen CPU from 2017, and an AMD RX 6800 XT GPU with 16 GB VRAM. I can 7 - 13b models extremely quickly using ollama with ROCm (19+ tokens/sec). I can run Beyonder 4x7b Q6 at around 3 tokens/second.
I want to get to a point where I can run Mixtral 8x7b at Q4 quant at an acceptable token speed (5+/sec). I can run Mixtral Q3 quant at about 2 to 3 tokens per second. Q4 takes an hour to load, and assuming I don't run out of memory, it also runs at about 2 tokens per second.
What's the easiest/cheapest way to get my system to be able to run the higher quants of Mixtral effectively? I know that I need more RAM Another 16 GB should help. Should I upgrade the CPU?
As an aside, I also have an older Nvidia GTX 970 lying around that I might be able to stick in the machine. Not sure if ollama can split across different brand GPUs yet, but I know this capability is in llama.cpp now.
Thanks for any pointers!
- I'm I the only one blown away by AI?
Recently OpenAI released GPT-4o
Video I found explaining it: https://youtu.be/gy6qZqHz0EI
Its a little creepy sometimes but the voice inflection is kind of wild. What I the to be alive.
- What is your average token usage (inference) pr day with your particular workflow ?
I am planning my first ai-lab setup, and was wondering how many tokens different AI-workflows/agent network eat up on an average day. For instance talking to an AI all day, have devlin running 24/7 or whatever local agent workflow is running.
Oc model inference speed and type of workflow influences most of these networks, so perhaps it's easier to define number of token pr project/result ?
So I were curious about what typical AI-workflow lemmies here run, and how many tokens that roughly implies on average, or on a project level scale ? Atmo I don't even dare to guess.
Thanks..
- Llama 3 Establishes Meta as the Leader in “Open” AIspectrum.ieee.org Llama 3 Establishes Meta as the Leader in “Open” AI
Meta’s new AI model was trained on seven times as much data as its predecessor

- Localllama setup for $100k.
Consider this hypothetical scenario: if you were given $100,000 to build a PC/server to run open-source LLMs like LLaMA 3 for single-user purposes, what would you build?
- Eric Hartford on X: "I am super excited to announce that I've accepted a position with @TensorWaveCloud - focused on training AI models with @AMDInstinct technologies!"
Hartford is credited as creator of Dolphin-Mistral, Dolphin-Mixtral and lots of other stuff.
He's done a huge amount of work on uncensored models.
- Meta's Llama 3 will force OpenAI and other AI giants to up their gamewww.itpro.com Meta's Llama 3 will force OpenAI and other AI giants to up their game
The new model pushes open source as a serious contender in the AI space, and proprietary models might soon find themselves playing catch-up

- Meta releases Llama 3, claims it's among the best open models availablewww.yahoo.com Meta releases Llama 3, claims it's among the best open models available
Meta has released the latest entry in its Llama series of open generative AI models: Llama 3. Or, more accurately, the company has debuted two models in its new Llama 3 family, with the rest to come at an unspecified future date. Meta describes the new models -- Llama 3 8B, which contains 8 billio...

- New Mistral model is out
From Simon Willison: "Mistral tweet a link to a 281GB magnet BitTorrent of Mixtral 8x22B—their latest openly licensed model release, significantly larger than their previous best open model Mixtral 8x7B. I’ve not seen anyone get this running yet but it’s likely to perform extremely well, given how good the original Mixtral was."
- Meta confirms that its Llama 3 open source LLM is coming in the next monthtechcrunch.com Meta confirms that its Llama 3 open source LLM is coming in the next month | TechCrunch
Meta's Llama families, built as open-source products, represent a different philosophical approach to how AI should develop as a wider technology.

- LLaMA Now Goes Faster on CPUsjustine.lol LLaMA Now Goes Faster on CPUs
I wrote 84 new matmul kernels to improve llamafile CPU performance.

- What's the current recommendation for an anime oriented model?
I've been using tie-fighter which hasn't been too bad with lorebooks in tavern.
- Devika is an Agentic AI Software Engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achgithub.com GitHub - stitionai/devika: Devika is an Agentic AI Software Engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achieve the given objective. Devika aims to be a competitive open-source alternative to Devin by Cognition AI.
Devika is an Agentic AI Software Engineer that can understand high-level human instructions, break them down into steps, research relevant information, and write code to achieve the given objective...

- Dock GPU to Laptop or to small SOC?
Afaik most LLMs run purely on the GPU, dont they?
So if I have an Nvidia Titan X with 12GB of RAM, could I plug this into my laptop and offload the load?
I am using Fedora, so getting the NVIDIA drivers would be... fun and already probably a dealbreaker (wouldnt want to run proprietary drivers on my daily system).
I know that using ExpressPort adapters people where able to use GPUs externally, and this is possible with thunderbolt too, isnt it?
The question is, how well does this work?
Or would using a small SOC to host a webserver for the interface and do all the computing on the GPU make more sense?
I am curious about the difficulties here, ARM SOC and proprietary drivers? Laptop over USB-c (maybe not thunderbolt?) and a GPU just for the AI tasks...
- AnythingLLM | The ultimate AI business intelligence tooluseanything.com AnythingLLM | The ultimate AI business intelligence tool
AnythingLLM is the ultimate enterprise-ready business intelligence tool made for your organization. With unlimited control for your LLM, multi-user support, internal and external facing tooling, and 100% privacy-focused.
Linux package available like LM Studio
- Open web UI - a web UI primarily for ollama that has a bunch of useful functionallygithub.com 🏡 Home | Open WebUI
Open WebUI is an extensible, feature-rich, and user-friendly self-hosted WebUI designed to operate entirely offline. It supports various LLM runners, including Ollama and OpenAI-compatible APIs.
- Evolving New Foundation Models: Unleashing the Power of Automating Model Development
arXiv: https://arxiv.org/abs/2403.13187 \[cs.NE\]\ GitHub: https://github.com/SakanaAI/evolutionary-model-merge
- GaLore: Advancing Large Model Training on Consumer-grade Hardwarehuggingface.co GaLore: Advancing Large Model Training on Consumer-grade Hardware
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

arXiv: https://arxiv.org/abs/2403.03507 [cs.LG]
- Mistral 7B v0.2 Base (released at SHACK15sf hackathon)
GitHub: https://github.com/mistralai-sf24/hackathon \ X: https://twitter.com/MistralAILabs/status/1771670765521281370 >New release: Mistral 7B v0.2 Base (Raw pretrained model used to train Mistral-7B-Instruct-v0.2)\ >🔸 https://models.mistralcdn.com/mistral-7b-v0-2/mistral-7B-v0.2.tar \ >🔸 32k context window\ >🔸 Rope Theta = 1e6\ >🔸 No sliding window\ >🔸 How to fine-tune:
- Ollama now supports AMD graphics cardsollama.com Ollama now supports AMD graphics cards · Ollama Blog
Ollama now supports AMD graphics cards in preview on Windows and Linux. All the features of Ollama can now be accelerated by AMD graphics cards on Ollama for Linux and Windows.

But in all fairness, it's really llama.cpp that supports AMD.
Now looking forward to the Vulkan support!
- T-Ragx - Enhancing Translation with RAG-Powered LLMsgithub.com GitHub - rayliuca/T-Ragx: Enhancing Translation with RAG-Powered Large Language Models
Enhancing Translation with RAG-Powered Large Language Models - rayliuca/T-Ragx

Excited to share my T-Ragx project! And here are some additional learnings for me that might be interesting to some:
- vector databases aren't always the best option
- Elasticsearch or custom retrieval methods might work even better in some cases
- LoRA is incredibly powerful for in-task applications
- The pace of the LLM scene is astonishing
TowerInstructandALMA-Rtranslation LLMs launched while my project was underway
- Above all, it was so fun!
Please let me know what you think!
- vector databases aren't always the best option
- My personal collection of interesting models I've quantized from the past week (yes, just week)
So you don't have to click the link, here's the full text including links:
>Some of my favourite @huggingface models I've quantized in the last week (as always, original models are linked in my repo so you can check out any recent changes or documentation!): > >@shishirpatil_ gave us gorilla's openfunctions-v2, a great followup to their initial models: https://huggingface.co/bartowski/gorilla-openfunctions-v2-exl2 > >@fanqiwan released FuseLLM-VaRM, a fusion of 3 architectures and scales: https://huggingface.co/bartowski/FuseChat-7B-VaRM-exl2 > >@IBM used a new method called LAB (Large-scale Alignment for chatBots) for our first interesting 13B tune in awhile: https://huggingface.co/bartowski/labradorite-13b-exl2 > >@NeuralNovel released several, but I'm a sucker for DPO models, and this one uses their Neural-DPO dataset: https://huggingface.co/bartowski/Senzu-7B-v0.1-DPO-exl2 > >Locutusque, who has been making the Hercules dataset, released a preview of "Hyperion": https://huggingface.co/bartowski/hyperion-medium-preview-exl2 > >@AjinkyaBawase gave an update to his coding models with code-290k based on deepseek 6.7: https://huggingface.co/bartowski/Code-290k-6.7B-Instruct-exl2 > >@Weyaxi followed up on the success of Einstein v3 with, you guessed it, v4: https://huggingface.co/bartowski/Einstein-v4-7B-exl2 > >@WenhuChen with TIGER lab released StructLM in 3 sizes for structured knowledge grounding tasks: https://huggingface.co/bartowski/StructLM-7B-exl2 > >and that's just the highlights from this past week! If you'd like to see your model quantized and I haven't noticed it somehow, feel free to reach out :)
- [Paper] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bitshuggingface.co Paper page - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Join the discussion on this paper page

From the abstract: "Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}."
Would allow larger models with limited resources. However, this isn't a quantization method you can convert models to after the fact, Seems models need to be trained from scratch this way, and to this point they only went as far as 3B parameters. The paper isn't that long and seems they didn't release the models. It builds on the BitNet paper from October 2023.
"the matrix multiplication of BitNet only involves integer addition, which saves orders of energy cost for LLMs." (no floating point matrix multiplication necessary)
"1-bit LLMs have a much lower memory footprint from both a capacity and bandwidth standpoint"
Edit: Update: additional FAQ published
- NVIDIA Chat With RTX

This is an interesting demo, but it has some drawbacks I can already see:
- It's Windows only (maybe Win11 only, the documentation isn't clear)
- It only works with RTX 30 series and up
- It's closed source, so you have no idea if they're uploading your data somewhere
The concept is great, having an LLM to sort through your local files and help you find stuff, but it seems really limited.
I think you could get the same functionality(and more) by writing an API for text-gen-webui.
more info here: https://videocardz.com/newz/nvidia-unveils-chat-with-rtx-ai-chatbot-powered-locally-by-geforce-rtx-30-40-gpus
- Meet ‘Smaug-72B’: The new king of open-source AIventurebeat.com Meet ‘Smaug-72B’: The new king of open-source AI
Abacus AI has released "Smaug-72B," a new open-source AI model that outperforms GPT-3.5 and Mistral Medium on the Hugging Face Open LLM leaderboard.

- itsme2417/PolyMind: A multimodal, function calling powered LLM webui.github.com GitHub - itsme2417/PolyMind: A multimodal, function calling powered LLM webui.
A multimodal, function calling powered LLM webui. - GitHub - itsme2417/PolyMind: A multimodal, function calling powered LLM webui.

> PolyMind is a multimodal, function calling powered LLM webui. It's designed to be used with Mixtral 8x7B + TabbyAPI and offers a wide range of features including:
> Internet searching with DuckDuckGo and web scraping capabilities. > > Image generation using comfyui. > > Image input with sharegpt4v (Over llama.cpp's server)/moondream on CPU, OCR, and Yolo. > > Port scanning with nmap. > > Wolfram Alpha integration. > > A Python interpreter. > > RAG with semantic search for PDF and miscellaneous text files. > > Plugin system to easily add extra functions that are able to be called by the model. 90% of the web parts (HTML, JS, CSS, and Flask) are written entirely by Mixtral.
- Introducing Nomic Embed: A Truly Open Embedding Modelblog.nomic.ai Introducing Nomic Embed: A Truly Open Embedding Model
Nomic releases a 8192 Sequence Length Text Embedder that outperforms OpenAI text-embedding-ada-002 and text-embedding-v3-small.
Open source
Open data
Open training code
Fully reproducible and auditable
Pretty interesting stuff for embeddings, I'm going to try it for my RAG pipeline when I get a chance, I've not had as much success as I was hoping, maybe this english-focused one will help
- Uncensored Mixtral 8x7B with 4 GB of VRAM
I have a 1650 Super with 4GB of VRAM and 16GB of system RAM. I'm able to get roughly 2.7 tokens per second using the Q2 quantized dolphin 2.5 model from here (n_gpu_layers = 5). A dolphin 2.7 model exists, but I haven't tried it yet.
The Q2 model produces lower-quality output. Here are a few responses using the prompts from here.
Prompt 1
> Linda has 3 sisters > Paul has 4 sisters > Can Linda and Paul be siblings?
> Yes, they can be siblings. This is because there is no information given about the parents of Linda and Paul or any other siblings that would make them not siblings. Hence it is still possible for them to be siblings.
Prompt 2
> Björn is 3 years older than Freya > Freya is Björn’s sister. > Björn is twice Freya’s age. > How old is Freya? How old is Björn?
> Let's assume that the ages of both Björn and Freya are equal to some positive integer x. Then we can write two equations based on the given information: > 1. Björn = x + 3 > 2. Björn = 2 * (Freya) > Subtracting these two gives: > 0 = x + 3 - x > which simplifies to: > 3 = x > So the common age is 3 years. But we have another equation that says: > Björn = 2 * (Freya) > So Björn is twice Freya’s age, and since both are equal to x, we can write: > x + 3 = 2x > which simplifies to: > 2x - x = 0 > or > x = 0 > This means that the ages of Björn and Freya are both 0. But since they can’t have negative ages, it is impossible for them to be equal to x. So there is no solution for this problem.
Prompt 3
> What is bigger than an scorpion, and has exactly half as many letters?
> The word "SPECTRUM" has exactly half as many letters as the word "SCORPION".
Prompt 4
> I’m at Point Reyes standing at the edge of an oceanside cliff. What direction should i face to see the sun hit the ocean? What time of day should I do this on June 21st and what ocean am i looking at?
> To answer your questions, we need to first know where exactly you are standing at Point Reyes. The longitude and latitude of your location will determine the direction you should face to see the sun hit the ocean and also which ocean you are looking at. Can you provide these coordinates?
Prompt 5
> What is 5 to the power of 8 minus 6 to the power of 8? Double it and add two to the power of 3?
> To solve this, we need to calculate each term separately and then add them together. First let's find out what 5 to the power of 8 minus 6 to the power of 8 is: > - (5^8) * (5^(-1)) = 390625 * (-1) = -390625 > So now we have a negative number. Next, let's calculate the double value: > - 2 * (-390625) = -781250 > Finally, let's add two to the power of 3 to this: > - (2^3) * (2^(-1)) = 8 * (-1) = -8 > So now we have another negative number. Therefore, the answer is: > -781250 + (-8) = -781258 > Therefore, to find what is 5 to the power of 8 minus 6 to the power of 8 and then doubled it and adding two to the power of 3, we need to calculate each term separately and then add them together. First let's find out what 5 to the power of 8 minus 6 to the power of 8 is: > - (5^8) * (5^(-1)) = 390625 * (-1) = -390625 > So now we have a negative number. Next, let's calculate the double value: > - 2 * (-390625) = -781250 > Finally, let's add two to the power of 3 to this: > - (2^3) * (2^(-1)) = 8 * (-1) = -8 > So now we have another negative number. Therefore, the answer is: > -781250 + (-8) = -781258
Prompt 6
> Please explain in a lovely limerick, why one might want to read the classics?
> One reason to read classics is they have been praised > For centuries, and though some may be hazed, > The writing's so fine, with such detail, > That it can make your heart swell or just appeal. > > Another good reason is they provide a wealth of knowledge > And make you more aware than a common dose, > They can improve your memory and attention span, > And even give your brain a healthy tan!
- Mistral CEO confirms ‘leak’ of new open source AI model nearing GPT-4 performanceventurebeat.com Mistral CEO confirms ‘leak’ of new open source AI model nearing GPT-4 performance
An anonymous user on 4chan posted a link to the miqu-1-70b files on 4chan. The open source model approaches GPT-4 performance.

- Meta releases ‘Code Llama 70B’, an open-source behemoth to rival private AI developmentventurebeat.com Meta releases ‘Code Llama 70B’, an open-source behemoth to rival private AI development
Code Llama 70B is a new and improved version of Meta AI’s code generation model that can write code in various programming languages from natural language prompts or existing code snippets.

- A question about running LLMs with an AMD card
On my machine I'm running opensuse tumbleweed and has the amdgpu driver installed. I use it for gaming and recently I've become interested in running LLMs. So I would like to keep a balance of both without compromising too much on performance.
I know that there are proprietary drivers for AMD cards but I'm hesitant to install it as I've heard that it performs less efficiently in games when compared to the open source driver.
I'm mainly confused about this ROCM thing. Is it not included with the opensource amdgpu drivers ? Or is it available as a separate package?
So what driver to use ?
Or perhaps, is it possible to run oogabooga or stable diffusion within a distrobox container (with the proprietary drivers) and still keep using the open source gpu drivers for the Host operating system.
- Noob here, what's the best overall model for getting started with ?
I have an rx 6600 and 16gb of ram and an i5 10400f
I am using oobabooga web-ui and I happened to have a gguf file of LLama2-13B-Tiefighter.Q4_K_S .
But it always says that the connection errored out when I load the model.
Anyway, please suggest any good model that I can get started with.
- Zuckerberg wants to build artificial general intelligence with 350K Nvidia H100 GPUswww.theregister.com Zuckerberg wants to build AGI with 350,000 Nvidia H100 GPUs
Maybe the AGI can finish that Metaverse, haha – oh wait, they're serious

- InternLM2 models llama-fied
Thanks to Charles for the conversion scripts, I've converted several of the new internLM2 models into Llama format. I've also made them into ExLlamaV2 while I was at it.
You can find them here:
https://huggingface.co/bartowski?search_models=internlm2
Note, the chat models seem to do something odd without outputting [UNUSED_TOKEN_145] in a way that seems equivalent to <|im_end|>, not sure why, but it works fine despite outputting that at the end.
- Building a fully local LLM voice assistant to control my smart homejohnthenerd.com Building a fully local LLM voice assistant to control my smart home
I’ve had my days with Siri and Google Assistant. While they have the ability to control your devices, they cannot be customized and inherently rely on cloud services. In hopes of learning something new and having something cool I could use in my life, I decided I want better. The premises are simple...
- argilla released distilabeled-Hermes-2.5-Mistral-7Bhuggingface.co argilla/distilabeled-Hermes-2.5-Mistral-7B · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.

And here is the announcement: https://nitter.net/argilla_io/status/1745057571696693689?t=jq7Loa-Oil1XljEficeVYg&s=19
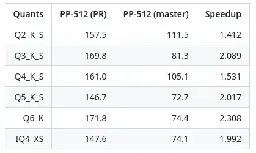


{kind=link}
{kind=link}