Llama 2 & WizardLM Megathread
Starting another model megathread to aggregate resources for any newcomers.
It's been awhile since I've had a chance to chat with some of these models so let me know some your favorites in the comments below.
There are many to choose from - sharing your experience could help someone else decide which to download for their use-case.
Thread Models:
---
Quantized Base Llama-2 Chat Models
Llama-2-7b-Chat
GPTQ
GGUF
AWQ
---
Llama-2-13B-chat
GPTQ
GGUF
AWQ
---
Llama-2-70B-chat
GPTQ
GGUF
AWQ
---
Quantized WizardLM Models
WizardLM-7B-V1.0+
GPTQ
GGUF
AWQ
---
WizardLM-13B-V1.0+
GPTQ
GGUF
AWQ
---
WizardLM-30B-V1.0+
GPTQ
- WizardLM-30B-uncensored-GPTQ
- WizardLM-Uncensored-SuperCOT-StoryTelling-30B-GPTQ
- WizardLM-33B-V1.0-Uncensored-GPTQ
GGUF
- WizardLM-30B-GGUF
- WizardLM-Uncensored-SuperCOT-StoryTelling-30B-GGUF
- WizardLM-33B-V1.0-Uncensored-GGUF
AWQ
---
Llama 2 Resources
> LLaMA 2 is a large language model developed by Meta and is the successor to LLaMA 1. LLaMA 2 is available for free for research and commercial use through providers like AWS, Hugging Face, and others. LLaMA 2 pretrained models are trained on 2 trillion tokens, and have double the context length than LLaMA 1. Its fine-tuned models have been trained on over 1 million human annotations.
Llama 2 Benchmarks
> Llama 2 shows strong improvements over prior LLMs across diverse NLP benchmarks, especially as model size increases: On well-rounded language tests like MMLU and AGIEval, Llama-2-70B scores 68.9% and 54.2% - far above MTP-7B, Falcon-7B, and even the 65B Llama 1 model.
Llama 2 Tutorials
Tutorials by James Briggs (also link above) are quick, hands-on ways for you to experiment with Llama 2 workflows. See also a poor man's guide to fine-tuning Llama 2. Check out Replicate if you want to host Llama 2 with an easy-to-use API.
---
Did I miss any models? What are some of your favorites? Which family/foundation/fine-tuning should we cover next?
cross-posted from: https://lemmy.world/post/6399678
> # 🤖 Happy FOSAI Friday! 🚀
>
> Friday, October 6, 2023
>
> ## HyperTech News Report #0003
>
> Hello Everyone!
>
> This week highlights a wave of new papers and frameworks that expand upon LLM functionalities. With a tsunami of applications on the horizon I foresee a bedrock of tools to preceed. I'm not sure what kits and processes will end up part of this bedrock, but I hope some of these methods end up interesting or helpful to your workflow!
>
> ### Table of Contents
> - Community Changelog
> - Image of the Week
> - News
> - Tools & Frameworks
> - Papers
>
> ### Community Changelog
>
> - Pinned Mistral Megathread
> - We're R&D'ing FOSAI Models!
>
> ## Image of the Week
>
> !
>
> This image of the week comes from one of my own projects! I hope you don't mind me sharing.. I was really happy with this result. This was generated from an SDXL model I trained and host on Replicate. I use an mock ensemble approach to generate various game assets for an experimental roguelike I'm making with a colleague.
>
> My current method is not at all efficient, but I have fun. Right now, I have three SDXL models I interact with, each generating art I can use for my project. Andraxus takes care of wallpapers and in-game levels (this image you're seeing here), his
> in-game companion Biazera imagines characters and entities of this world, while Cerephelo tinkers and toils over the machinations within - crafting items, loot, powerups, etc.
>
> I've been hesitant self-promoting here. But if there's genuine interest in this project I would be more than happy sharing more details. It's still in pre-alpha development, but there were plans releasing all of the models we use as open-source (obviously). We're still working on the engine though. Let me know if you want to see more on this project.
>
> ---
>
> ## News
>
> ---
>
> 1. Arxiv Publications Workflow: A new workflow has been introduced that allows users to scrape search topics from Arxiv, converting the results into markdown (MD) format. This makes it easier to digest and understand topics from Arxiv published content. The tool, available on GitHub, is particularly useful for those who wish to delve deeper into research papers and run their own research processes.
>
> 2. Texting LLMs from Your Phone: A guide has been shared that enables users to communicate with their personal assistants via simple text messages. The process involves setting up a Twilio account, purchasing and registering a phone number, and then integrating it with the Replicate platform. The code, available on GitHub, makes it possible to send and receive messages from LLMs directly on one's phone.
>
> 3. Microsoft's AutoGen: Microsoft has released AutoGen, a tool designed to aid in the creation of autonomous LLM agents. Compatible with ChatGPT models, AutoGen facilitates the development of LLM applications using multiple agents that can converse with each other to solve tasks. The framework is customizable and allows for seamless human participation. More details can be found on GitHub.
>
> 4. Promptbench and ACE Framework: Promptbench is a new project focused on the evaluation and benchmarking of models. Stemming from the DyVal paper, it aims to provide reliable insights into model performance. On the other hand, the ACE Framework, designed for autonomous cognitive entities, offers a unique approach to agent tooling. While still in its early stages, it promises to bring about innovative implementations in the realms of personal assistants, game world NPCs, autonomous employees, and embodied robots.
>
> 5. Research Highlights: Several papers have been published that delve into the intricacies of LLMs. One paper introduces a method to enhance the zero-shot reasoning abilities of LLMs, while another, titled DyVal, proposes a dynamic evaluation protocol for LLMs. Additionally, the concept of Low-Rank Adapters (LoRA) ensembles for LLM fine-tuning has been explored, emphasizing the potential of using one model and dynamically swapping the fine-tuned QLoRA adapters.
>
> ---
>
> ## Tools & Frameworks
>
> ---
>
> #### Keep Up w/ Arxiv Publications
>
> - GitHub
> - Learn More
>
> Due to a drastic change in personal and work schedules, I've had to shift how I research and develop posts and projects for you guys. That being said, I found this workflow from the same author of the ACE Framework particularly helpful. It scrapes a search topic from Arxiv and returns a massive XML that is converted to markdown (MD) to then be used as an injectable context report for a LLM of your choosing (to further break down and understand topics) or as a well of information for the classic CTRL + F search. But at this point, info is aggregated (and human readable) from Arxiv published content.
>
> After reading abstractions you can further drill into each paper and dissect / run your own research processes as you see fit. There is definitely more room for automation and organization here I'm sure, but this has been a big resource for me lately so I wanted to proliferate it for others who might find it helpful too.
>
> #### Text LLMs from Your Phone
>
> - GitHub
> - Learn More
>
> I had an itch to make my personal assistants more accessible - so I started investigating ways I could simply text them from my iPhone (via simple sms). There are many other ways I could've done this, but texting has been something I always like to default to in communications. So, I found this cool guide that uses infra I already prefer (Replicate) and has a bonus LangChain integration - which opens up the door to a ton of other opportunities down the line.
>
> This tutorial was pretty straightforward - but to be honest, making the Twilio account, buying a phone number (then registering it) took the longest. The code itself takes less than 10 minutes to get up and running with ngrok. Super simple and straightforward there. The Twilio process? Not so much.. but it was worth the pain!
>
> I am still waiting on my phone number to be verified (so that the Replicate inference endpoint can actually send SMS back to me) but I ended the night successfully texting the server on my local PC. It was wild texting the Ahsoka example from my phone and seeing the POST response return (even though it didn't go through SMS I could still see the server successfully receive my incoming message/prompt). I think there's a lot of fun to be had giving casual phone numbers and personalities to assistants like this. Especially if you want to LangChain some functions beyond just the conversation. If there's more interest on this topic, I can share how my assistant evolves once it gets full access to return SMS. I am designing this to streamline my personal life, and if it proves to be useful I will absolutely release the project as open-source.
>
> #### AutoGen
>
> - GitHub
> - Learn More
> - Tutorial
>
> With Agents on the rise, tools and automation pipelines to build them have become increasingly more important to consider. It seems like Microsoft is well aware of this, and thus released AutoGen, a tool to help enable this automation tooling and creation of autonomous LLM agents. AutoGen is compatible with ChatGPT models and is being kitted for local LLMs as we speak.
>
> > AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
>
> #### Promptbench
>
> - GitHub
> - Learn More
>
> I recently found promptbench - a project that seems to have stemmed from the DyVal paper (shared below). I for one appreciate some of the new tools that are releasing focused around the evaluation and benchmarking of models. I hope we continue to see more evals, benchmarks, and projects that return us insights we can rely upon.
>
> #### ACE Framework
>
> !
>
> - GitHub
> - Learn More
>
> A new framework has been proposed and designed for autonomous cognitive entities. This appears similar to agents and their style of tooling, but with a different architecture approach? I don't believe implementation of this is ready, but it may be soon and something to keep an eye on.
>
> > There are many possible implementations of the ACE Framework. Rather than detail every possible permutation, here is a list of categories that we perceive as likely and viable.
>
> > Personal Assistant and/or Companion
>
> > - This is a self-contained version of ACE that is intended to interact with one user.
> > - Think of Cortana from HALO, Samantha from HER, or Joi from Blade Runner 2049. (yes, we recognize these are all sexualized female avatars)
> > - The idea would be to create something that is effectively a personal Executive Assistant that is able to coordinate, plan, research, and solve problems for you.
> This could be deployed on mobile, smart home devices, laptops, or web sites.
>
> > Game World NPC's
>
> > - This is a kind of game character that has their own personality, motivations, agenda, and objectives. Furthermore, they would have their own unique memories.
> > - This can give NPCs a much more realistic ability to pursue their own objectives, which should make game experiences much more dynamic and unpredictable, thus raising novelty.
> These can be adapted to 2D or 3D game engines such as PyGame, Unity, or Unreal.
>
> > Autonomous Employee
>
> > - This is a version of the ACE that is meant to carry out meaningful and productive work inside a corporation.
> > - Whether this is a digital CSR or backoffice worker depends on the deployment.
> > - It could also be a "digital team member" that primarily interacts via Discord, Slack, or Microsoft Teams.
>
> > Embodied Robot
>
> > The ACE Framework is ideal to create self-contained, autonomous machines. Whether they are domestic aid robots or something like WALL-E
>
> ---
>
> ## Papers
>
> ---
>
> Agent Instructs Large Language Models to be General Zero-Shot Reasoners
>
>
> > We introduce a method to improve the zero-shot reasoning abilities of large language models on general language understanding tasks. Specifically, we build an autonomous agent to instruct the reasoning process of large language models. We show this approach further unleashes the zero-shot reasoning abilities of large language models to more tasks. We study the performance of our method on a wide set of datasets spanning generation, classification, and reasoning. We show that our method generalizes to most tasks and obtains state-of-the-art zero-shot performance on 20 of the 29 datasets that we evaluate. For instance, our method boosts the performance of state-of-the-art large language models by a large margin, including Vicuna-13b (13.3%), Llama-2-70b-chat (23.2%), and GPT-3.5 Turbo (17.0%). Compared to zero-shot chain of thought, our improvement in reasoning is striking, with an average increase of 10.5%. With our method, Llama-2-70b-chat outperforms zero-shot GPT-3.5 Turbo by 10.2%.
>
> DyVal: Graph-informed Dynamic Evaluation of Large Language Models
>
>
> - https://llm-eval.github.io/
> - https://github.com/microsoft/promptbench
>
> > Large language models (LLMs) have achieved remarkable performance in various evaluation benchmarks. However, concerns about their performance are raised on potential data contamination in their considerable volume of training corpus. Moreover, the static nature and fixed complexity of current benchmarks may inadequately gauge the advancing capabilities of LLMs. In this paper, we introduce DyVal, a novel, general, and flexible evaluation protocol for dynamic evaluation of LLMs. Based on our proposed dynamic evaluation framework, we build graph-informed DyVal by leveraging the structural advantage of directed acyclic graphs to dynamically generate evaluation samples with controllable complexities. DyVal generates challenging evaluation sets on reasoning tasks including mathematics, logical reasoning, and algorithm problems. We evaluate various LLMs ranging from Flan-T5-large to ChatGPT and GPT4. Experiments demonstrate that LLMs perform worse in DyVal-generated evaluation samples with different complexities, emphasizing the significance of dynamic evaluation. We also analyze the failure cases and results of different prompting methods. Moreover, DyVal-generated samples are not only evaluation sets, but also helpful data for fine-tuning to improve the performance of LLMs on existing benchmarks. We hope that DyVal can shed light on the future evaluation research of LLMs.
>
> LoRA ensembles for large language model fine-tuning
>
> > Finetuned LLMs often exhibit poor uncertainty quantification, manifesting as overconfidence, poor calibration, and unreliable prediction results on test data or out-of-distribution samples. One approach commonly used in vision for alleviating this issue is a deep ensemble, which constructs an ensemble by training the same model multiple times using different random initializations. However, there is a huge challenge to ensembling LLMs: the most effective LLMs are very, very large. Keeping a single LLM in memory is already challenging enough: keeping an ensemble of e.g. 5 LLMs in memory is impossible in many settings. To address these issues, we propose an ensemble approach using Low-Rank Adapters (LoRA), a parameter-efficient fine-tuning technique. Critically, these low-rank adapters represent a very small number of parameters, orders of magnitude less than the underlying pre-trained model. Thus, it is possible to construct large ensembles of LoRA adapters with almost the same computational overhead as using the original model. We find that LoRA ensembles, applied on its own or on top of pre-existing regularization techniques, gives consistent improvements in predictive accuracy and uncertainty quantification.
>
> There is something to be discovered between LoRA, QLoRA, and ensemble/MoE designs. I am digging into this niche because of an interesting bit I heard from sentdex (if you want to skip to the part I'm talking about, go to 13:58). Around 15:00 minute mark he brings up QLoRA adapters (nothing new) but his approach was interesting.
>
> He eventually shares he is working on a QLoRA ensemble approach with skunkworks (presumably Boeing skunkworks). This confirmed my suspicion. Better yet - he shared his thoughts on how all of this could be done. Watch and support his video for more insights, but the idea boils down to using one model and dynamically swapping the fine-tuned QLoRA adapters. I think this is a highly efficient and unapplied approach. Especially in that MoE and ensemble realm of design. If you're reading this and understood anything I said - get to building! This is a seriously interesting idea that could yield positive results. I will share my findings when I find the time to dig into this more.
>
> ---
>
> ### Author's Note
>
> This post was authored by the moderator of !fosai@lemmy.world - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> ### Thanks for Reading!
>
> This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now... if you found anything about this post interesting, consider subscribing to !fosai@lemmy.world where you can join us on the journey into the great unknown!
>
> Until next time!
>
> #### Blaed
{kind=link}
{kind=link}
cross-posted from: https://lemmy.world/post/6399678
> # 🤖 Happy FOSAI Friday! 🚀
>
> Friday, October 6, 2023
>
> ## HyperTech News Report #0003
>
> Hello Everyone!
>
> This week highlights a wave of new papers and frameworks that expand upon LLM functionalities. With a tsunami of applications on the horizon I foresee a bedrock of tools to preceed. I'm not sure what kits and processes will end up part of this bedrock, but I hope some of these methods end up interesting or helpful to your workflow!
>
> ### Table of Contents
> - Community Changelog
> - Image of the Week
> - News
> - Tools & Frameworks
> - Papers
>
> ### Community Changelog
>
> - Pinned Mistral Megathread
> - We're R&D'ing FOSAI Models!
>
> ## Image of the Week
>
> !
>
> This image of the week comes from one of my own projects! I hope you don't mind me sharing.. I was really happy with this result. This was generated from an SDXL model I trained and host on Replicate. I use an mock ensemble approach to generate various game assets for an experimental roguelike I'm making with a colleague.
>
> My current method is not at all efficient, but I have fun. Right now, I have three SDXL models I interact with, each generating art I can use for my project. Andraxus takes care of wallpapers and in-game levels (this image you're seeing here), his
> in-game companion Biazera imagines characters and entities of this world, while Cerephelo tinkers and toils over the machinations within - crafting items, loot, powerups, etc.
>
> I've been hesitant self-promoting here. But if there's genuine interest in this project I would be more than happy sharing more details. It's still in pre-alpha development, but there were plans releasing all of the models we use as open-source (obviously). We're still working on the engine though. Let me know if you want to see more on this project.
>
> ---
>
> ## News
>
> ---
>
> 1. Arxiv Publications Workflow: A new workflow has been introduced that allows users to scrape search topics from Arxiv, converting the results into markdown (MD) format. This makes it easier to digest and understand topics from Arxiv published content. The tool, available on GitHub, is particularly useful for those who wish to delve deeper into research papers and run their own research processes.
>
> 2. Texting LLMs from Your Phone: A guide has been shared that enables users to communicate with their personal assistants via simple text messages. The process involves setting up a Twilio account, purchasing and registering a phone number, and then integrating it with the Replicate platform. The code, available on GitHub, makes it possible to send and receive messages from LLMs directly on one's phone.
>
> 3. Microsoft's AutoGen: Microsoft has released AutoGen, a tool designed to aid in the creation of autonomous LLM agents. Compatible with ChatGPT models, AutoGen facilitates the development of LLM applications using multiple agents that can converse with each other to solve tasks. The framework is customizable and allows for seamless human participation. More details can be found on GitHub.
>
> 4. Promptbench and ACE Framework: Promptbench is a new project focused on the evaluation and benchmarking of models. Stemming from the DyVal paper, it aims to provide reliable insights into model performance. On the other hand, the ACE Framework, designed for autonomous cognitive entities, offers a unique approach to agent tooling. While still in its early stages, it promises to bring about innovative implementations in the realms of personal assistants, game world NPCs, autonomous employees, and embodied robots.
>
> 5. Research Highlights: Several papers have been published that delve into the intricacies of LLMs. One paper introduces a method to enhance the zero-shot reasoning abilities of LLMs, while another, titled DyVal, proposes a dynamic evaluation protocol for LLMs. Additionally, the concept of Low-Rank Adapters (LoRA) ensembles for LLM fine-tuning has been explored, emphasizing the potential of using one model and dynamically swapping the fine-tuned QLoRA adapters.
>
> ---
>
> ## Tools & Frameworks
>
> ---
>
> #### Keep Up w/ Arxiv Publications
>
> - GitHub
> - Learn More
>
> Due to a drastic change in personal and work schedules, I've had to shift how I research and develop posts and projects for you guys. That being said, I found this workflow from the same author of the ACE Framework particularly helpful. It scrapes a search topic from Arxiv and returns a massive XML that is converted to markdown (MD) to then be used as an injectable context report for a LLM of your choosing (to further break down and understand topics) or as a well of information for the classic CTRL + F search. But at this point, info is aggregated (and human readable) from Arxiv published content.
>
> After reading abstractions you can further drill into each paper and dissect / run your own research processes as you see fit. There is definitely more room for automation and organization here I'm sure, but this has been a big resource for me lately so I wanted to proliferate it for others who might find it helpful too.
>
> #### Text LLMs from Your Phone
>
> - GitHub
> - Learn More
>
> I had an itch to make my personal assistants more accessible - so I started investigating ways I could simply text them from my iPhone (via simple sms). There are many other ways I could've done this, but texting has been something I always like to default to in communications. So, I found this cool guide that uses infra I already prefer (Replicate) and has a bonus LangChain integration - which opens up the door to a ton of other opportunities down the line.
>
> This tutorial was pretty straightforward - but to be honest, making the Twilio account, buying a phone number (then registering it) took the longest. The code itself takes less than 10 minutes to get up and running with ngrok. Super simple and straightforward there. The Twilio process? Not so much.. but it was worth the pain!
>
> I am still waiting on my phone number to be verified (so that the Replicate inference endpoint can actually send SMS back to me) but I ended the night successfully texting the server on my local PC. It was wild texting the Ahsoka example from my phone and seeing the POST response return (even though it didn't go through SMS I could still see the server successfully receive my incoming message/prompt). I think there's a lot of fun to be had giving casual phone numbers and personalities to assistants like this. Especially if you want to LangChain some functions beyond just the conversation. If there's more interest on this topic, I can share how my assistant evolves once it gets full access to return SMS. I am designing this to streamline my personal life, and if it proves to be useful I will absolutely release the project as open-source.
>
> #### AutoGen
>
> - GitHub
> - Learn More
> - Tutorial
>
> With Agents on the rise, tools and automation pipelines to build them have become increasingly more important to consider. It seems like Microsoft is well aware of this, and thus released AutoGen, a tool to help enable this automation tooling and creation of autonomous LLM agents. AutoGen is compatible with ChatGPT models and is being kitted for local LLMs as we speak.
>
> > AutoGen is a framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. AutoGen agents are customizable, conversable, and seamlessly allow human participation. They can operate in various modes that employ combinations of LLMs, human inputs, and tools.
>
> #### Promptbench
>
> - GitHub
> - Learn More
>
> I recently found promptbench - a project that seems to have stemmed from the DyVal paper (shared below). I for one appreciate some of the new tools that are releasing focused around the evaluation and benchmarking of models. I hope we continue to see more evals, benchmarks, and projects that return us insights we can rely upon.
>
> #### ACE Framework
>
> !
>
> - GitHub
> - Learn More
>
> A new framework has been proposed and designed for autonomous cognitive entities. This appears similar to agents and their style of tooling, but with a different architecture approach? I don't believe implementation of this is ready, but it may be soon and something to keep an eye on.
>
> > There are many possible implementations of the ACE Framework. Rather than detail every possible permutation, here is a list of categories that we perceive as likely and viable.
>
> > Personal Assistant and/or Companion
>
> > - This is a self-contained version of ACE that is intended to interact with one user.
> > - Think of Cortana from HALO, Samantha from HER, or Joi from Blade Runner 2049. (yes, we recognize these are all sexualized female avatars)
> > - The idea would be to create something that is effectively a personal Executive Assistant that is able to coordinate, plan, research, and solve problems for you.
> This could be deployed on mobile, smart home devices, laptops, or web sites.
>
> > Game World NPC's
>
> > - This is a kind of game character that has their own personality, motivations, agenda, and objectives. Furthermore, they would have their own unique memories.
> > - This can give NPCs a much more realistic ability to pursue their own objectives, which should make game experiences much more dynamic and unpredictable, thus raising novelty.
> These can be adapted to 2D or 3D game engines such as PyGame, Unity, or Unreal.
>
> > Autonomous Employee
>
> > - This is a version of the ACE that is meant to carry out meaningful and productive work inside a corporation.
> > - Whether this is a digital CSR or backoffice worker depends on the deployment.
> > - It could also be a "digital team member" that primarily interacts via Discord, Slack, or Microsoft Teams.
>
> > Embodied Robot
>
> > The ACE Framework is ideal to create self-contained, autonomous machines. Whether they are domestic aid robots or something like WALL-E
>
> ---
>
> ## Papers
>
> ---
>
> Agent Instructs Large Language Models to be General Zero-Shot Reasoners
>
>
> > We introduce a method to improve the zero-shot reasoning abilities of large language models on general language understanding tasks. Specifically, we build an autonomous agent to instruct the reasoning process of large language models. We show this approach further unleashes the zero-shot reasoning abilities of large language models to more tasks. We study the performance of our method on a wide set of datasets spanning generation, classification, and reasoning. We show that our method generalizes to most tasks and obtains state-of-the-art zero-shot performance on 20 of the 29 datasets that we evaluate. For instance, our method boosts the performance of state-of-the-art large language models by a large margin, including Vicuna-13b (13.3%), Llama-2-70b-chat (23.2%), and GPT-3.5 Turbo (17.0%). Compared to zero-shot chain of thought, our improvement in reasoning is striking, with an average increase of 10.5%. With our method, Llama-2-70b-chat outperforms zero-shot GPT-3.5 Turbo by 10.2%.
>
> DyVal: Graph-informed Dynamic Evaluation of Large Language Models
>
>
> - https://llm-eval.github.io/
> - https://github.com/microsoft/promptbench
>
> > Large language models (LLMs) have achieved remarkable performance in various evaluation benchmarks. However, concerns about their performance are raised on potential data contamination in their considerable volume of training corpus. Moreover, the static nature and fixed complexity of current benchmarks may inadequately gauge the advancing capabilities of LLMs. In this paper, we introduce DyVal, a novel, general, and flexible evaluation protocol for dynamic evaluation of LLMs. Based on our proposed dynamic evaluation framework, we build graph-informed DyVal by leveraging the structural advantage of directed acyclic graphs to dynamically generate evaluation samples with controllable complexities. DyVal generates challenging evaluation sets on reasoning tasks including mathematics, logical reasoning, and algorithm problems. We evaluate various LLMs ranging from Flan-T5-large to ChatGPT and GPT4. Experiments demonstrate that LLMs perform worse in DyVal-generated evaluation samples with different complexities, emphasizing the significance of dynamic evaluation. We also analyze the failure cases and results of different prompting methods. Moreover, DyVal-generated samples are not only evaluation sets, but also helpful data for fine-tuning to improve the performance of LLMs on existing benchmarks. We hope that DyVal can shed light on the future evaluation research of LLMs.
>
> LoRA ensembles for large language model fine-tuning
>
> > Finetuned LLMs often exhibit poor uncertainty quantification, manifesting as overconfidence, poor calibration, and unreliable prediction results on test data or out-of-distribution samples. One approach commonly used in vision for alleviating this issue is a deep ensemble, which constructs an ensemble by training the same model multiple times using different random initializations. However, there is a huge challenge to ensembling LLMs: the most effective LLMs are very, very large. Keeping a single LLM in memory is already challenging enough: keeping an ensemble of e.g. 5 LLMs in memory is impossible in many settings. To address these issues, we propose an ensemble approach using Low-Rank Adapters (LoRA), a parameter-efficient fine-tuning technique. Critically, these low-rank adapters represent a very small number of parameters, orders of magnitude less than the underlying pre-trained model. Thus, it is possible to construct large ensembles of LoRA adapters with almost the same computational overhead as using the original model. We find that LoRA ensembles, applied on its own or on top of pre-existing regularization techniques, gives consistent improvements in predictive accuracy and uncertainty quantification.
>
> There is something to be discovered between LoRA, QLoRA, and ensemble/MoE designs. I am digging into this niche because of an interesting bit I heard from sentdex (if you want to skip to the part I'm talking about, go to 13:58). Around 15:00 minute mark he brings up QLoRA adapters (nothing new) but his approach was interesting.
>
> He eventually shares he is working on a QLoRA ensemble approach with skunkworks (presumably Boeing skunkworks). This confirmed my suspicion. Better yet - he shared his thoughts on how all of this could be done. Watch and support his video for more insights, but the idea boils down to using one model and dynamically swapping the fine-tuned QLoRA adapters. I think this is a highly efficient and unapplied approach. Especially in that MoE and ensemble realm of design. If you're reading this and understood anything I said - get to building! This is a seriously interesting idea that could yield positive results. I will share my findings when I find the time to dig into this more.
>
> ---
>
> ### Author's Note
>
> This post was authored by the moderator of !fosai@lemmy.world - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> ### Thanks for Reading!
>
> This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now... if you found anything about this post interesting, consider subscribing to !fosai@lemmy.world where you can join us on the journey into the great unknown!
>
> Until next time!
>
> #### Blaed
Hey everyone!
I think it's time we had a fosai model on HuggingFace. I'd like to start collecting ideas, strategies, and approaches for fine-tuning our first community model.
I'm open to hearing what you think we should do. We will release more in time. This is just the beginning.
For now, I say let's pick a current open-source foundation model and fine-tune on datasets we all curate together, built around a loose concept of using a fine-tuned LLM to teach ourselves more bleeding-edge technologies (and how to build them using technical tools and concepts).
FOSAI is a non-profit movement. You own everything fosai as much as I do. It is synonymous with the concept of FOSS. It is for everyone to champion as they see fit. Anyone is welcome to join me in training or tuning using the workflows I share along the way.
You are encouraged to leverage fosai tools to create and express ideas of your own. All fosai models will be licensed under Apache 2.0. I am open to hearing thoughts if other licenses should be considered.
---
We're Building FOSAI Models! 🤖
Our goal is to fine-tune a foundation model and open-source it. We're going to start with one foundation family with smaller parameters (7B/13B) then work our way up to 40B (or other sizes), moving to the next as we vote on what foundation we should fine-tune as a community.
---
Fine-Tuned Use Case ☑️
Technical
FOSAI Model Idea #1- Research & Development AssistantFOSAI Model Idea #2- Technical Project ManagerFOSAI Model Idea #3- Personal Software DeveloperFOSAI Model Idea #4- Life Coach / Teacher / MentorFOSAI Model Idea #5- FOSAI OS / System Assistant
Non-Technical
FOSAI Model Idea #6- Dungeon Master / Lore MasterFOSAI Model Idea #7- Sentient Robot CharacterFOSAI Model Idea #8- Friendly Companion CharacterFOSAI Model Idea #9- General RPG or Sci-Fi CharacterFOSAI Model Idea #10- Philosophical Character
OR
FOSAI Foundation Model ☑️
---
Foundation Model ☑️
(Pick one)
MistralLlama 2Falcon..(Your Submission Here)
---
Model Name & Convention
snake_case_exampleCamelCaseExamplekebab-case-example
0.) FOSAI ☑️
fosai-7Bfosai-13B
1.) FOSAI Assistant ☑️
fosai-assitant-7Bfosai-assistant-13B
2.) FOSAI Atlas ☑️
fosai-atlas-7Bfosai-atlas-13B
3.) FOSAI Navigator ☑️
fosai-navigator-7Bfosai-navigator-13B
4.) ?
---
Datasets ☑️
TBD!What datasets do you think we should fine-tune on?
---
Alignment ☑️
To embody open-source mentalities, I think it's worth releasing both censored and uncensored versions of our models. This is something I will consider as we train and fine-tune over time. Like any tool, you are responsible for your usage and how you choose to incorporate into your business and/or personal life.
---
License ☑️
All fosai models will be licensed under Apache 2.0. I am open to hearing thoughts if other licenses should be considered.
This will be a fine-tuned model, so it may inherit some of the permissions and license agreements as its foundation model and have other implications depending on your country or local law.
Generally speaking, you can expect that all fosai models will be commercially viable through the selection process of its foundation family and the post-processing steps that are fine-tuning the model.
---
Costs
I will be personally covering all training and deployment costs. This may change if I choose to put together some sort of patronage, but for now - don't worry about this. I will be using something like RunPod or some other custom deployed solution for training.
---
Cast Your Votes! ☑️
Share Your Ideas & Vote in the Comments Below! ✅
What do you want to see out of this first community model? What are some of the fine-tuning ideas you've wanted to try, but never had the time or chance to test? Let me know in the comments and we'll brainstorm together.
I am in no rush to get this out, so I will leave this up for everyone to see and interact with until I feel we have a solid direction we can all agree upon. There will be plenty of more opportunities to create, curate, and customize more fosai models I plan to release in the future.
Update [10/25/23]: I may have found a fine-tuning workflow for both Llama (2) and Mistral, but I haven't had any time to validate the first test run. Once I have a chance to do this and test some inference I'll be updating this post with the workflow, the models, and some sample output with example datasets. Unfortunately, I have ran out of personal funds to allocate to training, so it is unsure when I will have a chance to make another attempt at this if this first attempt doesn't pan out. Will keep everyone posted as we approach the end of 2023.
cross-posted from: https://lemmy.world/post/5965315
> # 🤖 Happy FOSAI Friday! 🚀
>
> Friday, September 29, 2023
>
> ## HyperTech News Report #0002
>
> Hello Everyone!
>
> Welcome back to the HyperTech News Report! This week we're seeing some really exciting developments in futuristic technologies. With more tools and methods releasing by the day, I feel we're in for a renaissance in software. I hope hardware is soon to follow.. but I am here for it! So are you. Brace yourselves. Change is coming! This next year will be very interesting to watch unfold.
>
> #### Table of Contents
> - New Foundation Model!
> - Metaverse Developments
> - NVIDIA NeMo Guardrails
> - Tutorial Highlights
>
> #### Community Changelog
>
> - Cleaned up some old content (let me know if you notice something that should be archived or updated)
>
> ### Image of the Week
> !
>
> This image of the week comes from a DALL-E 3 demonstration by Will Depue. This depicts a popular image for diffusion models benchmarks - the astronaut riding a horse in space. Apparently this was hard to get right, and others have had trouble replicating it - but it seems to have been generated by DALL-E 3 nevertheless. Curious to see how it stacks up against other diffusers when its more widely available.
>
> ### New Foundation Model!
>
> There have been many new models hitting HuggingFace on the daily. The recent influx has made it hard to benchmark and keep up with these models - so I will be highlighting a hand select curated week-by-week, exploring these with more focus (a few at a time).
>
> If you have any model favorites (or showcase suggestions) let me know what they are in the comments below and I'll add them to the growing catalog!
>
> This week we're taking a look at Mistral - a new foundation model with a sliding attention mechanism that gives it advantages over other models. Better yet - the mistral.ai team released this new model under the Apache 2.0 license. Massive shoutout to this team, this is huge for anyone who wants more options (commercially) outside of Llama 2 and Falcon families.
>
> From Mistralai:
>
> > The best 7B, Apache 2.0.. Mistral-7B-v0.1 is a small, yet powerful model adaptable to many use-cases. Mistral 7B is better than Llama 2 13B on all benchmarks, has natural coding abilities, and 8k sequence length. It’s released under Apache 2.0 licence, and we made it easy to deploy on any cloud.
>
> Learn More
>
> Mistralai
> - https://huggingface.co/mistralai/Mistral-7B-v0.1
> - https://mistral.ai/news/announcing-mistral-7b/
> - https://docs.mistral.ai/quickstart/
>
> TheBloke (Quantized)
> - https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF
> https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPT
>
> More About GPTQ
> - https://github.com/ggerganov/llama.cpp/pull/1827
>
> More About GGUF
> - https://github.com/ggerganov/llama.cpp/pull/2398#issuecomment-1682837610
>
> ### Metaverse Developments
>
> Mark Zuckerberg had his third round interview on the Lex Fridman podcast - but this time, in the updated Metaverse. This is pretty wild. We seem to have officially left uncanny valley territory. There are still clearly bugs and improvements to be made - but imagine the possibilities of this mixed reality technology (paired with VR LLM applications).
>
> The type of experiences we can begin to explore in these digital realms are going to evolve into things of true sci-fi in our near future. This is all very exciting stuff to look forward to as AI proliferates markets and drives innovation.
>
> What do you think? Zuck looks more human in the metaverse than in real life.. mission.. success?
>
> Click here for the podcast episode.
>
> ### NVIDIA NeMo Guardrails
>
> If you haven't heard about NeMo Guardrails, you should check it out. It is a new library and approach for aligning models and completing functions for LLMs. It is similar to LangChain and LlamaIndex, but uses an in-house developed language from NVIDIA called 'colang' for configuration, with NeMo Guardrail libraries in python friendly syntax.
>
> This is still a new and unexplored tool, but could provide some interesting results with some creative applications. It is also particularly powerful if you need to align enterprise LLMs for clients or stakeholders.
>
> Learn More
>
> ### Tutorial Highlights
>
> Mistral 7B - Small But Mighty 🚀 🚀
> - https://www.youtube.com/watch?v=z4wPiallZcI&ab_channel=PromptEngineering
>
> Chatbots with RAG: LangChain Full Walkthrough
> - https://www.youtube.com/watch?v=LhnCsygAvzY&ab_channel=JamesBriggs
>
> NVIDIA NeMo Guardrails: Full Walkthrough for Chatbots / AI
> - https://www.youtube.com/watch?v=SwqusllMCnE&t=1s&ab_channel=JamesBriggs
>
> ### Author's Note
>
> This post was authored by the moderator of !fosai@lemmy.world - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> ### Thanks for Reading!
>
> If you found anything about this post interesting, consider subscribing to !fosai@lemmy.world where I do my best to keep you informed about free open-source artificial intelligence as it emerges in real-time.
>
> Our community is quickly becoming a living time capsule thanks to the rapid innovation of this field. If you've gotten this far, I cordially invite you to join us and dance along the path to AGI and the great unknown.
>
> Come on in, the water is fine, the gates are wide open! You're still early to the party, so there is still plenty of wonder and discussion yet to be had in our little corner of the digiverse.
>
> This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now...
>
> Until next time!
>
> #### Blaed
{kind=link}
cross-posted from: https://lemmy.world/post/5965315
> # 🤖 Happy FOSAI Friday! 🚀
>
> Friday, September 29, 2023
>
> ## HyperTech News Report #0002
>
> Hello Everyone!
>
> Welcome back to the HyperTech News Report! This week we're seeing some really exciting developments in futuristic technologies. With more tools and methods releasing by the day, I feel we're in for a renaissance in software. I hope hardware is soon to follow.. but I am here for it! So are you. Brace yourselves. Change is coming! This next year will be very interesting to watch unfold.
>
> #### Table of Contents
> - New Foundation Model!
> - Metaverse Developments
> - NVIDIA NeMo Guardrails
> - Tutorial Highlights
>
> #### Community Changelog
>
> - Cleaned up some old content (let me know if you notice something that should be archived or updated)
>
> ### Image of the Week
> !
>
> This image of the week comes from a DALL-E 3 demonstration by Will Depue. This depicts a popular image for diffusion models benchmarks - the astronaut riding a horse in space. Apparently this was hard to get right, and others have had trouble replicating it - but it seems to have been generated by DALL-E 3 nevertheless. Curious to see how it stacks up against other diffusers when its more widely available.
>
> ### New Foundation Model!
>
> There have been many new models hitting HuggingFace on the daily. The recent influx has made it hard to benchmark and keep up with these models - so I will be highlighting a hand select curated week-by-week, exploring these with more focus (a few at a time).
>
> If you have any model favorites (or showcase suggestions) let me know what they are in the comments below and I'll add them to the growing catalog!
>
> This week we're taking a look at Mistral - a new foundation model with a sliding attention mechanism that gives it advantages over other models. Better yet - the mistral.ai team released this new model under the Apache 2.0 license. Massive shoutout to this team, this is huge for anyone who wants more options (commercially) outside of Llama 2 and Falcon families.
>
> From Mistralai:
>
> > The best 7B, Apache 2.0.. Mistral-7B-v0.1 is a small, yet powerful model adaptable to many use-cases. Mistral 7B is better than Llama 2 13B on all benchmarks, has natural coding abilities, and 8k sequence length. It’s released under Apache 2.0 licence, and we made it easy to deploy on any cloud.
>
> Learn More
>
> Mistralai
> - https://huggingface.co/mistralai/Mistral-7B-v0.1
> - https://mistral.ai/news/announcing-mistral-7b/
> - https://docs.mistral.ai/quickstart/
>
> TheBloke (Quantized)
> - https://huggingface.co/TheBloke/Mistral-7B-v0.1-GGUF
> https://huggingface.co/TheBloke/Mistral-7B-v0.1-GPT
>
> More About GPTQ
> - https://github.com/ggerganov/llama.cpp/pull/1827
>
> More About GGUF
> - https://github.com/ggerganov/llama.cpp/pull/2398#issuecomment-1682837610
>
> ### Metaverse Developments
>
> Mark Zuckerberg had his third round interview on the Lex Fridman podcast - but this time, in the updated Metaverse. This is pretty wild. We seem to have officially left uncanny valley territory. There are still clearly bugs and improvements to be made - but imagine the possibilities of this mixed reality technology (paired with VR LLM applications).
>
> The type of experiences we can begin to explore in these digital realms are going to evolve into things of true sci-fi in our near future. This is all very exciting stuff to look forward to as AI proliferates markets and drives innovation.
>
> What do you think? Zuck looks more human in the metaverse than in real life.. mission.. success?
>
> Click here for the podcast episode.
>
> ### NVIDIA NeMo Guardrails
>
> If you haven't heard about NeMo Guardrails, you should check it out. It is a new library and approach for aligning models and completing functions for LLMs. It is similar to LangChain and LlamaIndex, but uses an in-house developed language from NVIDIA called 'colang' for configuration, with NeMo Guardrail libraries in python friendly syntax.
>
> This is still a new and unexplored tool, but could provide some interesting results with some creative applications. It is also particularly powerful if you need to align enterprise LLMs for clients or stakeholders.
>
> Learn More
>
> ### Tutorial Highlights
>
> Mistral 7B - Small But Mighty 🚀 🚀
> - https://www.youtube.com/watch?v=z4wPiallZcI&ab_channel=PromptEngineering
>
> Chatbots with RAG: LangChain Full Walkthrough
> - https://www.youtube.com/watch?v=LhnCsygAvzY&ab_channel=JamesBriggs
>
> NVIDIA NeMo Guardrails: Full Walkthrough for Chatbots / AI
> - https://www.youtube.com/watch?v=SwqusllMCnE&t=1s&ab_channel=JamesBriggs
>
> ### Author's Note
>
> This post was authored by the moderator of !fosai@lemmy.world - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> ### Thanks for Reading!
>
> If you found anything about this post interesting, consider subscribing to !fosai@lemmy.world where I do my best to keep you informed about free open-source artificial intelligence as it emerges in real-time.
>
> Our community is quickly becoming a living time capsule thanks to the rapid innovation of this field. If you've gotten this far, I cordially invite you to join us and dance along the path to AGI and the great unknown.
>
> Come on in, the water is fine, the gates are wide open! You're still early to the party, so there is still plenty of wonder and discussion yet to be had in our little corner of the digiverse.
>
> This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now...
>
> Until next time!
>
> #### Blaed
cross-posted from: https://lemmy.world/post/5549499
> # 🤖 Happy FOSAI Friday! 🚀
>
> Friday, September 22, 2023
>
> ## HyperTech News Report #0001
>
> Hello Everyone!
>
> This series is a new vehicle for !fosai@lemmy.world news reports. In these posts I'll go over projects or news I stumble across week-over-week. I will try to keep Fridays consistent with this series, covering most of what I have been (but at regular cadence). For this week, I am going to do my best catching us up on a few old (and new) hot topics you may or may not have heard about already.
>
> #### Table of Contents
> - Introducing HyperTech
> - New GGUF Models
> - Falcon 180B
> - Llama 3 Rumors
> - DALM RAG Toolkit
> - DALL-E 3
>
> #### Community Changelog
>
> - Updated all resources on FOSAI ▲ XYZ.
> - Added new content to FOSAI ▲ XYZ.
> - Added new content and resources to the !fosai@lemmy.world sidebar.
> - Added HyperTech to !fosai@lemmy.world, reflecting personal workflows and processes.
> - All changes should be visible within the next 48 hours.
>
> ### Image of the Week
>
> A Stable Diffusion + ControlNet image garnered a ton of attention on social media this last week. This image has brought more recognition to the possibilities of these tools and helps shed a more positive light on the capabilities of generative models.
>
> Read More
>
> !
>
> ### Introducing HyperTech
>
> HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> HyperTech Workshop (V0.1.0)
>
> I am excited to announce my technology company: HyperTech. The first project of HyperionTechnologies is a digital workshop that comes in the form of a GitHub repo template for AI/ML/DL developers. HyperTech is a for-fun sci-fi company I started to explore AI development (among other emerging technologies I find curious and interesting). It is a satire corpo sandbox I have designed around my personal journey inside and outside of !fosai@lemmy.world with highly experimental projects and workflows. I will be using this company and setting/narrative/thematic to drive some of the future (and totally optional) content of our community. Any tooling, templates, or examples made along the way are entirely for you to learn from or reverse engineer for your own purpose or amusement. I'll be doing a dedicated post to HyperTech later this weekend. Keep your eye out for that if you're curious. The future is now. The future is bright. The future is HYPERION. (don't take this project too seriously).
>
> ### New GGUF Models
>
> Within this last month or so, llama.cpp have begun to standardize a new model format - the .GGUF model - which is much more optimized than its now legacy (and deprecated predecessor - GGML). This is a big deal for anyone running GGML models. GGUF is basically superior in all ways. Check out llama.cpp's notes about this change on their official GitHub. I have used a few GGUF models myself and have found them much more performant than any GGML counterpart. TheBloke has already converted many of his older models into this new format (which is compatible with anything utilizing llama.cpp).
>
> More About GGUF:
>
> > It is a successor file format to GGML, GGMF and GGJT, and is designed to be unambiguous by containing all the information needed to load a model. It is also designed to be extensible, so that new features can be added to GGML without breaking compatibility with older models. Basically: 1.) No more breaking changes 2.) Support for non-llama models. (falcon, rwkv, bloom, etc.) and 3.) No more fiddling around with rope-freq-base, rope-freq-scale, gqa, and rms-norm-eps. Prompt formats could also be set automatically.
>
> ### Falcon 180B
>
> Many of you have probably already heard of this, but Falcon 180B was recently announced - and I haven't covered it here yet so it's worth mentioning in this post. Check out the full article regarding its release here on HuggingFace. Can't wait to see what comes next! This will open up a lot of doors for us to explore.
>
> > Today, we're excited to welcome TII's Falcon 180B to HuggingFace! Falcon 180B sets a new state-of-the-art for open models. It is the largest openly available language model, with 180 billion parameters, and was trained on a massive 3.5 trillion tokens using TII's RefinedWeb dataset. This represents the longest single-epoch pretraining for an open model. The dataset for Falcon 180B consists predominantly of web data from RefinedWeb (~85%). In addition, it has been trained on a mix of curated data such as conversations, technical papers, and a small fraction of code (~3%). This pretraining dataset is big enough that even 3.5 trillion tokens constitute less than an epoch.
>
> > The released chat model is fine-tuned on chat and instruction datasets with a mix of several large-scale conversational datasets.
>
> > ‼️ Commercial Usage: Falcon 180b can be commercially used but under very restrictive conditions, excluding any "hosting use". We recommend to check the license and consult your legal team if you are interested in using it for commercial purposes.
>
> > You can find the model on the Hugging Face Hub (base and chat model) and interact with the model on the Falcon Chat Demo Space.
>
> ### LLama 3 Rumors
>
> Speaking of big open-source models - Llama 3 is rumored to be under training or development. Llama 2 was clearly an improvement over its predecessor. I wonder how Llama 3 & 4 will stack in this race to AGI. I forget that we're still early to this party. At this rate of development, I believe we're bound to see it within the decade.
>
> > Meta plans to rival GPT-4 with a rumored free Llama 3- According to an early rumor, Meta is working on Llama 3, which is intended to compete with GPT-4, but will remain largely free under the Llama license.- Jason Wei, an engineer associated with OpenAI, has indicated that Meta possesses the computational capacity to train Llama 3 to a level comparable to GPT-4. Furthermore, Wei suggests that the feasibility of training Llama 4 is already within reach.- Despite Wei's credibility, it's important to acknowledge the possibility of inaccuracies in his statements or the potential for shifts in these plans.
>
> ### DALM
>
> I recently stumbled across DALM - a new domain adapted language modeling toolkit which is supposed to enable a workflow that trains a retrieval augmented generation (RAG) pipeline from end-to-end. According to their results, the DALM specific training process leads to a much higher response quality when it comes to retrieval augmented generation. I haven't had a chance to tinker with this a lot, but I'd keep an eye on it if you're engaging with RAG workflows.
>
> DALM Manifesto:
>
> > A great rift has emerged between general LLMs and the vector stores that are providing them with contextual information. The unification of these systems is an important step in grounding AI systems in efficient, factual domains, where they are utilized not only for their generality, but for their specificity and uniqueness. To this end, we are excited to open source the Arcee Domain Adapted Language Model (DALM) toolkit for developers to build on top of our Arcee open source Domain Pretrained (DPT) LLMs. We believe that our efforts will help as we begin next phase of language modeling, where organizations deeply tailor AI to operate according to their unique intellectual property and worldview.
>
> > For the first time in the literature, we modified the initial RAG-end2end model (TACL paper, HuggingFace implementation) to work with decoder-only language models like Llama, Falcon, or GPT. We also incorporated the in-batch negative concept alongside the RAG's marginalization to make the entire process efficient.
>
> ### DALL-E 3
>
> OpenAI announced DALL-E 3 that will have direct native compatibility within ChatGPT. This means users should be able to naturally and semantically iterate over images and features over time, adjusting the output from the same chat interface throughout their conversation. This will enable many users to seamlessly incorporate image diffusion into their chat workflows.
>
> I think this is huge, mostly because it illustrates a new technique that removes some of the barriers that prompt engineers have to solve (it reads prompts differently than other diffusers). Not to mention you are permitted to sell, keep, and commercialize any image DALL-E generates.
>
> I am curious to see if open-source workflows can follow a similar approach and have iterative design workflows that seamlessly integrate with a chat interface. That, paired with manual tooling from things like ControlNet would be a powerful pairing that could spark a lot of creativity. Don't get me wrong, sometimes I really like manual and node-based workflows, but I believe semantic computation is the future. Regardless of how 'open' OpenAI truly is, these breakthroughs help chart the path forward for everyone else still catching up.
>
> More About DALL-E 3:
>
> > DALL·E 3 is now in research preview, and will be available to ChatGPT Plus and Enterprise customers in October, via the API and in Labs later this fall. Modern text-to-image systems have a tendency to ignore words or descriptions, forcing users to learn prompt engineering. DALL·E 3 represents a leap forward in our ability to generate images that exactly adhere to the text you provide. DALL·E 3 is built natively on ChatGPT, which lets you use ChatGPT as a brainstorming partner and refiner of your prompts. Just ask ChatGPT what you want to see in anything from a simple sentence to a detailed paragraph. When prompted with an idea, ChatGPT will automatically generate tailored, detailed prompts for DALL·E 3 that bring your idea to life. If you like a particular image, but it’s not quite right, you can ask ChatGPT to make tweaks with just a few words.
>
> > DALL·E 3 will be available to ChatGPT Plus and Enterprise customers in early October. As with DALL·E 2, the images you create with DALL·E 3 are yours to use and you don't need our permission to reprint, sell or merchandise them.
>
> ### Author's Note
>
> This post was authored by the moderator of !fosai@lemmy.world - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> ### Thanks for Reading!
>
> If you found anything about this post interesting, consider subscribing to !fosai@lemmy.world where I do my best to keep you informed about free open-source artificial intelligence as it emerges in real-time.
>
> Our community is quickly becoming a living time capsule thanks to the rapid innovation of this field. If you've gotten this far, I cordially invite you to join us and dance along the path to AGI and the great unknown.
>
> Come on in, the water is fine, the gates are wide open! You're still early to the party, so there is still plenty of wonder and discussion yet to be had in our little corner of the digiverse.
>
> This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now...
>
> Until next time!
>
> #### Blaed
{kind=link}
cross-posted from: https://lemmy.world/post/5549499
> # 🤖 Happy FOSAI Friday! 🚀
>
> Friday, September 22, 2023
>
> ## HyperTech News Report #0001
>
> Hello Everyone!
>
> This series is a new vehicle for !fosai@lemmy.world news reports. In these posts I'll go over projects or news I stumble across week-over-week. I will try to keep Fridays consistent with this series, covering most of what I have been (but at regular cadence). For this week, I am going to do my best catching us up on a few old (and new) hot topics you may or may not have heard about already.
>
> #### Table of Contents
> - Introducing HyperTech
> - New GGUF Models
> - Falcon 180B
> - Llama 3 Rumors
> - DALM RAG Toolkit
> - DALL-E 3
>
> #### Community Changelog
>
> - Updated all resources on FOSAI ▲ XYZ.
> - Added new content to FOSAI ▲ XYZ.
> - Added new content and resources to the !fosai@lemmy.world sidebar.
> - Added HyperTech to !fosai@lemmy.world, reflecting personal workflows and processes.
> - All changes should be visible within the next 48 hours.
>
> ### Image of the Week
>
> A Stable Diffusion + ControlNet image garnered a ton of attention on social media this last week. This image has brought more recognition to the possibilities of these tools and helps shed a more positive light on the capabilities of generative models.
>
> Read More
>
> !
>
> ### Introducing HyperTech
>
> HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> HyperTech Workshop (V0.1.0)
>
> I am excited to announce my technology company: HyperTech. The first project of HyperionTechnologies is a digital workshop that comes in the form of a GitHub repo template for AI/ML/DL developers. HyperTech is a for-fun sci-fi company I started to explore AI development (among other emerging technologies I find curious and interesting). It is a satire corpo sandbox I have designed around my personal journey inside and outside of !fosai@lemmy.world with highly experimental projects and workflows. I will be using this company and setting/narrative/thematic to drive some of the future (and totally optional) content of our community. Any tooling, templates, or examples made along the way are entirely for you to learn from or reverse engineer for your own purpose or amusement. I'll be doing a dedicated post to HyperTech later this weekend. Keep your eye out for that if you're curious. The future is now. The future is bright. The future is HYPERION. (don't take this project too seriously).
>
> ### New GGUF Models
>
> Within this last month or so, llama.cpp have begun to standardize a new model format - the .GGUF model - which is much more optimized than its now legacy (and deprecated predecessor - GGML). This is a big deal for anyone running GGML models. GGUF is basically superior in all ways. Check out llama.cpp's notes about this change on their official GitHub. I have used a few GGUF models myself and have found them much more performant than any GGML counterpart. TheBloke has already converted many of his older models into this new format (which is compatible with anything utilizing llama.cpp).
>
> More About GGUF:
>
> > It is a successor file format to GGML, GGMF and GGJT, and is designed to be unambiguous by containing all the information needed to load a model. It is also designed to be extensible, so that new features can be added to GGML without breaking compatibility with older models. Basically: 1.) No more breaking changes 2.) Support for non-llama models. (falcon, rwkv, bloom, etc.) and 3.) No more fiddling around with rope-freq-base, rope-freq-scale, gqa, and rms-norm-eps. Prompt formats could also be set automatically.
>
> ### Falcon 180B
>
> Many of you have probably already heard of this, but Falcon 180B was recently announced - and I haven't covered it here yet so it's worth mentioning in this post. Check out the full article regarding its release here on HuggingFace. Can't wait to see what comes next! This will open up a lot of doors for us to explore.
>
> > Today, we're excited to welcome TII's Falcon 180B to HuggingFace! Falcon 180B sets a new state-of-the-art for open models. It is the largest openly available language model, with 180 billion parameters, and was trained on a massive 3.5 trillion tokens using TII's RefinedWeb dataset. This represents the longest single-epoch pretraining for an open model. The dataset for Falcon 180B consists predominantly of web data from RefinedWeb (~85%). In addition, it has been trained on a mix of curated data such as conversations, technical papers, and a small fraction of code (~3%). This pretraining dataset is big enough that even 3.5 trillion tokens constitute less than an epoch.
>
> > The released chat model is fine-tuned on chat and instruction datasets with a mix of several large-scale conversational datasets.
>
> > ‼️ Commercial Usage: Falcon 180b can be commercially used but under very restrictive conditions, excluding any "hosting use". We recommend to check the license and consult your legal team if you are interested in using it for commercial purposes.
>
> > You can find the model on the Hugging Face Hub (base and chat model) and interact with the model on the Falcon Chat Demo Space.
>
> ### LLama 3 Rumors
>
> Speaking of big open-source models - Llama 3 is rumored to be under training or development. Llama 2 was clearly an improvement over its predecessor. I wonder how Llama 3 & 4 will stack in this race to AGI. I forget that we're still early to this party. At this rate of development, I believe we're bound to see it within the decade.
>
> > Meta plans to rival GPT-4 with a rumored free Llama 3- According to an early rumor, Meta is working on Llama 3, which is intended to compete with GPT-4, but will remain largely free under the Llama license.- Jason Wei, an engineer associated with OpenAI, has indicated that Meta possesses the computational capacity to train Llama 3 to a level comparable to GPT-4. Furthermore, Wei suggests that the feasibility of training Llama 4 is already within reach.- Despite Wei's credibility, it's important to acknowledge the possibility of inaccuracies in his statements or the potential for shifts in these plans.
>
> ### DALM
>
> I recently stumbled across DALM - a new domain adapted language modeling toolkit which is supposed to enable a workflow that trains a retrieval augmented generation (RAG) pipeline from end-to-end. According to their results, the DALM specific training process leads to a much higher response quality when it comes to retrieval augmented generation. I haven't had a chance to tinker with this a lot, but I'd keep an eye on it if you're engaging with RAG workflows.
>
> DALM Manifesto:
>
> > A great rift has emerged between general LLMs and the vector stores that are providing them with contextual information. The unification of these systems is an important step in grounding AI systems in efficient, factual domains, where they are utilized not only for their generality, but for their specificity and uniqueness. To this end, we are excited to open source the Arcee Domain Adapted Language Model (DALM) toolkit for developers to build on top of our Arcee open source Domain Pretrained (DPT) LLMs. We believe that our efforts will help as we begin next phase of language modeling, where organizations deeply tailor AI to operate according to their unique intellectual property and worldview.
>
> > For the first time in the literature, we modified the initial RAG-end2end model (TACL paper, HuggingFace implementation) to work with decoder-only language models like Llama, Falcon, or GPT. We also incorporated the in-batch negative concept alongside the RAG's marginalization to make the entire process efficient.
>
> ### DALL-E 3
>
> OpenAI announced DALL-E 3 that will have direct native compatibility within ChatGPT. This means users should be able to naturally and semantically iterate over images and features over time, adjusting the output from the same chat interface throughout their conversation. This will enable many users to seamlessly incorporate image diffusion into their chat workflows.
>
> I think this is huge, mostly because it illustrates a new technique that removes some of the barriers that prompt engineers have to solve (it reads prompts differently than other diffusers). Not to mention you are permitted to sell, keep, and commercialize any image DALL-E generates.
>
> I am curious to see if open-source workflows can follow a similar approach and have iterative design workflows that seamlessly integrate with a chat interface. That, paired with manual tooling from things like ControlNet would be a powerful pairing that could spark a lot of creativity. Don't get me wrong, sometimes I really like manual and node-based workflows, but I believe semantic computation is the future. Regardless of how 'open' OpenAI truly is, these breakthroughs help chart the path forward for everyone else still catching up.
>
> More About DALL-E 3:
>
> > DALL·E 3 is now in research preview, and will be available to ChatGPT Plus and Enterprise customers in October, via the API and in Labs later this fall. Modern text-to-image systems have a tendency to ignore words or descriptions, forcing users to learn prompt engineering. DALL·E 3 represents a leap forward in our ability to generate images that exactly adhere to the text you provide. DALL·E 3 is built natively on ChatGPT, which lets you use ChatGPT as a brainstorming partner and refiner of your prompts. Just ask ChatGPT what you want to see in anything from a simple sentence to a detailed paragraph. When prompted with an idea, ChatGPT will automatically generate tailored, detailed prompts for DALL·E 3 that bring your idea to life. If you like a particular image, but it’s not quite right, you can ask ChatGPT to make tweaks with just a few words.
>
> > DALL·E 3 will be available to ChatGPT Plus and Enterprise customers in early October. As with DALL·E 2, the images you create with DALL·E 3 are yours to use and you don't need our permission to reprint, sell or merchandise them.
>
> ### Author's Note
>
> This post was authored by the moderator of !fosai@lemmy.world - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> ### Thanks for Reading!
>
> If you found anything about this post interesting, consider subscribing to !fosai@lemmy.world where I do my best to keep you informed about free open-source artificial intelligence as it emerges in real-time.
>
> Our community is quickly becoming a living time capsule thanks to the rapid innovation of this field. If you've gotten this far, I cordially invite you to join us and dance along the path to AGI and the great unknown.
>
> Come on in, the water is fine, the gates are wide open! You're still early to the party, so there is still plenty of wonder and discussion yet to be had in our little corner of the digiverse.
>
> This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now...
>
> Until next time!
>
> #### Blaed
cross-posted from: https://lemmy.world/post/5549499
> # 🤖 Happy FOSAI Friday! 🚀
>
> Friday, September 22, 2023
>
> ## HyperTech News Report #0001
>
> Hello Everyone!
>
> This series is a new vehicle for !fosai@lemmy.world news reports. In these posts I'll go over projects or news I stumble across week-over-week. I will try to keep Fridays consistent with this series, covering most of what I have been (but at regular cadence). For this week, I am going to do my best catching us up on a few old (and new) hot topics you may or may not have heard about already.
>
> #### Table of Contents
> - Introducing HyperTech
> - New GGUF Models
> - Falcon 180B
> - Llama 3 Rumors
> - DALM RAG Toolkit
> - DALL-E 3
>
> #### Community Changelog
>
> - Updated all resources on FOSAI ▲ XYZ.
> - Added new content to FOSAI ▲ XYZ.
> - Added new content and resources to the !fosai@lemmy.world sidebar.
> - Added HyperTech to !fosai@lemmy.world, reflecting personal workflows and processes.
> - All changes should be visible within the next 48 hours.
>
> ### Image of the Week
>
> A Stable Diffusion + ControlNet image garnered a ton of attention on social media this last week. This image has brought more recognition to the possibilities of these tools and helps shed a more positive light on the capabilities of generative models.
>
> Read More
>
> !
>
> ### Introducing HyperTech
>
> HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> HyperTech Workshop (V0.1.0)
>
> I am excited to announce my technology company: HyperTech. The first project of HyperionTechnologies is a digital workshop that comes in the form of a GitHub repo template for AI/ML/DL developers. HyperTech is a for-fun sci-fi company I started to explore AI development (among other emerging technologies I find curious and interesting). It is a satire corpo sandbox I have designed around my personal journey inside and outside of !fosai@lemmy.world with highly experimental projects and workflows. I will be using this company and setting/narrative/thematic to drive some of the future (and totally optional) content of our community. Any tooling, templates, or examples made along the way are entirely for you to learn from or reverse engineer for your own purpose or amusement. I'll be doing a dedicated post to HyperTech later this weekend. Keep your eye out for that if you're curious. The future is now. The future is bright. The future is HYPERION. (don't take this project too seriously).
>
> ### New GGUF Models
>
> Within this last month or so, llama.cpp have begun to standardize a new model format - the .GGUF model - which is much more optimized than its now legacy (and deprecated predecessor - GGML). This is a big deal for anyone running GGML models. GGUF is basically superior in all ways. Check out llama.cpp's notes about this change on their official GitHub. I have used a few GGUF models myself and have found them much more performant than any GGML counterpart. TheBloke has already converted many of his older models into this new format (which is compatible with anything utilizing llama.cpp).
>
> More About GGUF:
>
> > It is a successor file format to GGML, GGMF and GGJT, and is designed to be unambiguous by containing all the information needed to load a model. It is also designed to be extensible, so that new features can be added to GGML without breaking compatibility with older models. Basically: 1.) No more breaking changes 2.) Support for non-llama models. (falcon, rwkv, bloom, etc.) and 3.) No more fiddling around with rope-freq-base, rope-freq-scale, gqa, and rms-norm-eps. Prompt formats could also be set automatically.
>
> ### Falcon 180B
>
> Many of you have probably already heard of this, but Falcon 180B was recently announced - and I haven't covered it here yet so it's worth mentioning in this post. Check out the full article regarding its release here on HuggingFace. Can't wait to see what comes next! This will open up a lot of doors for us to explore.
>
> > Today, we're excited to welcome TII's Falcon 180B to HuggingFace! Falcon 180B sets a new state-of-the-art for open models. It is the largest openly available language model, with 180 billion parameters, and was trained on a massive 3.5 trillion tokens using TII's RefinedWeb dataset. This represents the longest single-epoch pretraining for an open model. The dataset for Falcon 180B consists predominantly of web data from RefinedWeb (~85%). In addition, it has been trained on a mix of curated data such as conversations, technical papers, and a small fraction of code (~3%). This pretraining dataset is big enough that even 3.5 trillion tokens constitute less than an epoch.
>
> > The released chat model is fine-tuned on chat and instruction datasets with a mix of several large-scale conversational datasets.
>
> > ‼️ Commercial Usage: Falcon 180b can be commercially used but under very restrictive conditions, excluding any "hosting use". We recommend to check the license and consult your legal team if you are interested in using it for commercial purposes.
>
> > You can find the model on the Hugging Face Hub (base and chat model) and interact with the model on the Falcon Chat Demo Space.
>
> ### LLama 3 Rumors
>
> Speaking of big open-source models - Llama 3 is rumored to be under training or development. Llama 2 was clearly an improvement over its predecessor. I wonder how Llama 3 & 4 will stack in this race to AGI. I forget that we're still early to this party. At this rate of development, I believe we're bound to see it within the decade.
>
> > Meta plans to rival GPT-4 with a rumored free Llama 3- According to an early rumor, Meta is working on Llama 3, which is intended to compete with GPT-4, but will remain largely free under the Llama license.- Jason Wei, an engineer associated with OpenAI, has indicated that Meta possesses the computational capacity to train Llama 3 to a level comparable to GPT-4. Furthermore, Wei suggests that the feasibility of training Llama 4 is already within reach.- Despite Wei's credibility, it's important to acknowledge the possibility of inaccuracies in his statements or the potential for shifts in these plans.
>
> ### DALM
>
> I recently stumbled across DALM - a new domain adapted language modeling toolkit which is supposed to enable a workflow that trains a retrieval augmented generation (RAG) pipeline from end-to-end. According to their results, the DALM specific training process leads to a much higher response quality when it comes to retrieval augmented generation. I haven't had a chance to tinker with this a lot, but I'd keep an eye on it if you're engaging with RAG workflows.
>
> DALM Manifesto:
>
> > A great rift has emerged between general LLMs and the vector stores that are providing them with contextual information. The unification of these systems is an important step in grounding AI systems in efficient, factual domains, where they are utilized not only for their generality, but for their specificity and uniqueness. To this end, we are excited to open source the Arcee Domain Adapted Language Model (DALM) toolkit for developers to build on top of our Arcee open source Domain Pretrained (DPT) LLMs. We believe that our efforts will help as we begin next phase of language modeling, where organizations deeply tailor AI to operate according to their unique intellectual property and worldview.
>
> > For the first time in the literature, we modified the initial RAG-end2end model (TACL paper, HuggingFace implementation) to work with decoder-only language models like Llama, Falcon, or GPT. We also incorporated the in-batch negative concept alongside the RAG's marginalization to make the entire process efficient.
>
> ### DALL-E 3
>
> OpenAI announced DALL-E 3 that will have direct native compatibility within ChatGPT. This means users should be able to naturally and semantically iterate over images and features over time, adjusting the output from the same chat interface throughout their conversation. This will enable many users to seamlessly incorporate image diffusion into their chat workflows.
>
> I think this is huge, mostly because it illustrates a new technique that removes some of the barriers that prompt engineers have to solve (it reads prompts differently than other diffusers). Not to mention you are permitted to sell, keep, and commercialize any image DALL-E generates.
>
> I am curious to see if open-source workflows can follow a similar approach and have iterative design workflows that seamlessly integrate with a chat interface. That, paired with manual tooling from things like ControlNet would be a powerful pairing that could spark a lot of creativity. Don't get me wrong, sometimes I really like manual and node-based workflows, but I believe semantic computation is the future. Regardless of how 'open' OpenAI truly is, these breakthroughs help chart the path forward for everyone else still catching up.
>
> More About DALL-E 3:
>
> > DALL·E 3 is now in research preview, and will be available to ChatGPT Plus and Enterprise customers in October, via the API and in Labs later this fall. Modern text-to-image systems have a tendency to ignore words or descriptions, forcing users to learn prompt engineering. DALL·E 3 represents a leap forward in our ability to generate images that exactly adhere to the text you provide. DALL·E 3 is built natively on ChatGPT, which lets you use ChatGPT as a brainstorming partner and refiner of your prompts. Just ask ChatGPT what you want to see in anything from a simple sentence to a detailed paragraph. When prompted with an idea, ChatGPT will automatically generate tailored, detailed prompts for DALL·E 3 that bring your idea to life. If you like a particular image, but it’s not quite right, you can ask ChatGPT to make tweaks with just a few words.
>
> > DALL·E 3 will be available to ChatGPT Plus and Enterprise customers in early October. As with DALL·E 2, the images you create with DALL·E 3 are yours to use and you don't need our permission to reprint, sell or merchandise them.
>
> ### Author's Note
>
> This post was authored by the moderator of !fosai@lemmy.world - Blaed. I make games, produce music, write about tech, and develop free open-source artificial intelligence (FOSAI) for fun. I do most of this through a company called HyperionTechnologies a.k.a. HyperTech or HYPERION - a sci-fi company.
>
> ### Thanks for Reading!
>
> If you found anything about this post interesting, consider subscribing to !fosai@lemmy.world where I do my best to keep you informed about free open-source artificial intelligence as it emerges in real-time.
>
> Our community is quickly becoming a living time capsule thanks to the rapid innovation of this field. If you've gotten this far, I cordially invite you to join us and dance along the path to AGI and the great unknown.
>
> Come on in, the water is fine, the gates are wide open! You're still early to the party, so there is still plenty of wonder and discussion yet to be had in our little corner of the digiverse.
>
> This post was written by a human. For other humans. About machines. Who work for humans for other machines. At least for now...
>
> Until next time!
>
> #### Blaed
Hey everyone!
I don't think I've shared this one before, so allow me to introduce you to 'LM Studio' - a new application that is tailored to LLM developers and enthusiasts.
{kind=link}
Check it out!
- https://lmstudio.ai/
- https://github.com/lmstudio-ai
---
With LM Studio, you can ...
>🤖 - Run LLMs on your laptop, entirely offline
>👾 - Use models through the in-app Chat UI or an OpenAI compatible local server
>📂 - Download any compatible model files from HuggingFace 🤗 repositories
>🔭 - Discover new & noteworthy LLMs in the app's home page LM Studio supports any ggml Llama, MPT, and StarCoder model on Hugging Face (Llama 2, Orca, Vicuna, Nous Hermes, WizardCoder, MPT, etc.)
>Minimum requirements: M1/M2 Mac, or a Windows PC with a processor that supports AVX2. Linux is under development.
>Made possible thanks to the llama.cpp project.
>We are expanding our team. See our careers page.
---
Love seeing these new tools come out! Especially with the new gguf format being widely adopted.
The regularly updated and curated list of new LLM releases they provide through this platform is enough for me to keep it installed.
I'll be tinkering plenty when I have the time this week. I'll be sure to let everyone know how it goes! In the meantime, if you do end up giving LM Studio a try - let us know your thoughts and experience with it in the comments below.
Hello everyone!
I am working on figuring out better workflows bringing back more consistent post schedules. In the meantime, I'd like to leave you with a new update from LocalAI & Continue.
Check these projects out! More info from the Continue & LocalAI teams below:
Continue
- https://continue.dev/
- https://github.com/continuedev/continue
The open-source autopilot for software development A VS Code extension that brings the power of ChatGPT to your IDE
LocalAI
- https://localai.io/basics/news/
- https://github.com/go-skynet/LocalAI
LocalAI is a drop-in replacement REST API that’s compatible with OpenAI API specifications for local inferencing. It allows you to run LLMs (and not only) locally or on-prem with consumer grade hardware, supporting multiple model families that are compatible with the ggml format. Does not require GPU.
Combining the Power of Continue + LocalAI!
- https://github.com/go-skynet/LocalAI/blob/master/examples/continue/README.md
---
Note
From this release the llama backend supports only gguf files (see 943 ). LocalAI however still supports ggml files. We ship a version of llama.cpp before that change in a separate backend, named llama-stable to allow still loading ggml files. If you were specifying the llama backend manually to load ggml files from this release you should use llama-stable instead, or do not specify a backend at all (LocalAI will automatically handle this).
Continue
!logo
{kind=link}
This document presents an example of integration with continuedev/continue.
{kind=link}
For a live demonstration, please click on the link below:
Integration Setup Walkthrough
-
As outlined in
continue's documentation, install the Visual Studio Code extension from the marketplace and open it. -
In this example, LocalAI will download the gpt4all model and set it up as "gpt-3.5-turbo". Refer to the
docker-compose.yamlfile for details.```bash
Clone LocalAI
git clone https://github.com/go-skynet/LocalAI
cd LocalAI/examples/continue
Start with docker-compose
docker-compose up --build -d ```
-
Type
/configwithin Continue's VSCode extension, or edit the file located at~/.continue/config.pyon your system with the following configuration:```py from continuedev.src.continuedev.libs.llm.openai import OpenAI, OpenAIServerInfo
config = ContinueConfig( ... models=Models( default=OpenAI( api_key="my-api-key", model="gpt-3.5-turbo", openai_server_info=OpenAIServerInfo( api_base="http://localhost:8080", model="gpt-3.5-turbo" ) ) ), ) ```
This setup enables you to make queries directly to your model running in the Docker container. Note that the api_key does not need to be properly set up; it is included here as a placeholder.
If editing the configuration seems confusing, you may copy and paste the provided default config.py file over the existing one in ~/.continue/config.py after initializing the extension in the VSCode IDE.
Additional Resources
cross-posted from: https://lemmy.world/post/3879861
> # Beating GPT-4 on HumanEval with a Fine-Tuned CodeLlama-34B > > Hello everyone! This post marks an exciting moment for !fosai@lemmy.world and everyone in the open-source large language model and AI community. > > We appear to have a new contender on the block, a model apparently capable of surpassing OpenAI's state of the art ChatGPT-4 in coding evals (evaluations). > > This is huge. Not too long ago I made an offhand comment on us catching up to GPT-4 within a year. I did not expect that prediction to end up being reality in half the time. Let's hope this isn't a one-off scenario and that we see a new wave of open-source models that begin to challenge OpenAI. > > Buckle up, it's going to get interesting! > > Here's some notes from the blog, which you should visit and read in its entirety: > > - https://www.phind.com/blog/code-llama-beats-gpt4 > > --- > # Blog Post > > We have fine-tuned CodeLlama-34B and CodeLlama-34B-Python on an internal Phind dataset that achieved 67.6% and 69.5% pass@1 on HumanEval, respectively. GPT-4 achieved 67% according to their official technical report in March. To ensure result validity, we applied OpenAI's decontamination methodology to our dataset. > > The CodeLlama models released yesterday demonstrate impressive performance on HumanEval. > > - CodeLlama-34B achieved 48.8% pass@1 on HumanEval > - CodeLlama-34B-Python achieved 53.7% pass@1 on HumanEval > > We have fine-tuned both models on a proprietary dataset of ~80k high-quality programming problems and solutions. Instead of code completion examples, this dataset features instruction-answer pairs, setting it apart structurally from HumanEval. We trained the Phind models over two epochs, for a total of ~160k examples. LoRA was not used — both models underwent a native fine-tuning. We employed DeepSpeed ZeRO 3 and Flash Attention 2 to train these models in three hours using 32 A100-80GB GPUs, with a sequence length of 4096 tokens. > > Furthermore, we applied OpenAI's decontamination methodology to our dataset to ensure valid results, and found no contaminated examples. > > The methodology is: > > - For each evaluation example, we randomly sampled three substrings of 50 characters or used the entire example if it was fewer than 50 characters. > - A match was identified if any sampled substring was a substring of the processed training example. > > For further insights on the decontamination methodology, please refer to Appendix C of OpenAI's technical report. Presented below are the pass@1 scores we achieved with our fine-tuned models: > > - Phind-CodeLlama-34B-v1 achieved 67.6% pass@1 on HumanEval > - Phind-CodeLlama-34B-Python-v1 achieved 69.5% pass@1 on HumanEval > > ### Download > > We are releasing both models on Huggingface for verifiability and to bolster the open-source community. We welcome independent verification of results. > > - https://huggingface.co/Phind/Phind-CodeLlama-34B-v1 > - https://huggingface.co/Phind/Phind-CodeLlama-34B-Python-v1 > > --- > > If you get a chance to try either of these models out, let us know how it goes in the comments below! > > If you found anything about this post interesting, consider subscribing to !fosai@lemmy.world. > > Cheers to the power of open-source! May we continue the fight for optimization, efficiency, and performance.
cross-posted from: https://lemmy.world/post/3879861
> # Beating GPT-4 on HumanEval with a Fine-Tuned CodeLlama-34B > > Hello everyone! This post marks an exciting moment for !fosai@lemmy.world and everyone in the open-source large language model and AI community. > > We appear to have a new contender on the block, a model apparently capable of surpassing OpenAI's state of the art ChatGPT-4 in coding evals (evaluations). > > This is huge. Not too long ago I made an offhand comment on us catching up to GPT-4 within a year. I did not expect that prediction to end up being reality in half the time. Let's hope this isn't a one-off scenario and that we see a new wave of open-source models that begin to challenge OpenAI. > > Buckle up, it's going to get interesting! > > Here's some notes from the blog, which you should visit and read in its entirety: > > - https://www.phind.com/blog/code-llama-beats-gpt4 > > --- > # Blog Post > > We have fine-tuned CodeLlama-34B and CodeLlama-34B-Python on an internal Phind dataset that achieved 67.6% and 69.5% pass@1 on HumanEval, respectively. GPT-4 achieved 67% according to their official technical report in March. To ensure result validity, we applied OpenAI's decontamination methodology to our dataset. > > The CodeLlama models released yesterday demonstrate impressive performance on HumanEval. > > - CodeLlama-34B achieved 48.8% pass@1 on HumanEval > - CodeLlama-34B-Python achieved 53.7% pass@1 on HumanEval > > We have fine-tuned both models on a proprietary dataset of ~80k high-quality programming problems and solutions. Instead of code completion examples, this dataset features instruction-answer pairs, setting it apart structurally from HumanEval. We trained the Phind models over two epochs, for a total of ~160k examples. LoRA was not used — both models underwent a native fine-tuning. We employed DeepSpeed ZeRO 3 and Flash Attention 2 to train these models in three hours using 32 A100-80GB GPUs, with a sequence length of 4096 tokens. > > Furthermore, we applied OpenAI's decontamination methodology to our dataset to ensure valid results, and found no contaminated examples. > > The methodology is: > > - For each evaluation example, we randomly sampled three substrings of 50 characters or used the entire example if it was fewer than 50 characters. > - A match was identified if any sampled substring was a substring of the processed training example. > > For further insights on the decontamination methodology, please refer to Appendix C of OpenAI's technical report. Presented below are the pass@1 scores we achieved with our fine-tuned models: > > - Phind-CodeLlama-34B-v1 achieved 67.6% pass@1 on HumanEval > - Phind-CodeLlama-34B-Python-v1 achieved 69.5% pass@1 on HumanEval > > ### Download > > We are releasing both models on Huggingface for verifiability and to bolster the open-source community. We welcome independent verification of results. > > - https://huggingface.co/Phind/Phind-CodeLlama-34B-v1 > - https://huggingface.co/Phind/Phind-CodeLlama-34B-Python-v1 > > --- > > If you get a chance to try either of these models out, let us know how it goes in the comments below! > > If you found anything about this post interesting, consider subscribing to !fosai@lemmy.world. > > Cheers to the power of open-source! May we continue the fight for optimization, efficiency, and performance.
cross-posted from: https://lemmy.world/post/3879861
> # Beating GPT-4 on HumanEval with a Fine-Tuned CodeLlama-34B > > Hello everyone! This post marks an exciting moment for !fosai@lemmy.world and everyone in the open-source large language model and AI community. > > We appear to have a new contender on the block, a model apparently capable of surpassing OpenAI's state of the art ChatGPT-4 in coding evals (evaluations). > > This is huge. Not too long ago I made an offhand comment on us catching up to GPT-4 within a year. I did not expect that prediction to end up being reality in half the time. Let's hope this isn't a one-off scenario and that we see a new wave of open-source models that begin to challenge OpenAI. > > Buckle up, it's going to get interesting! > > Here's some notes from the blog, which you should visit and read in its entirety: > > - https://www.phind.com/blog/code-llama-beats-gpt4 > > --- > # Blog Post > > We have fine-tuned CodeLlama-34B and CodeLlama-34B-Python on an internal Phind dataset that achieved 67.6% and 69.5% pass@1 on HumanEval, respectively. GPT-4 achieved 67% according to their official technical report in March. To ensure result validity, we applied OpenAI's decontamination methodology to our dataset. > > The CodeLlama models released yesterday demonstrate impressive performance on HumanEval. > > - CodeLlama-34B achieved 48.8% pass@1 on HumanEval > - CodeLlama-34B-Python achieved 53.7% pass@1 on HumanEval > > We have fine-tuned both models on a proprietary dataset of ~80k high-quality programming problems and solutions. Instead of code completion examples, this dataset features instruction-answer pairs, setting it apart structurally from HumanEval. We trained the Phind models over two epochs, for a total of ~160k examples. LoRA was not used — both models underwent a native fine-tuning. We employed DeepSpeed ZeRO 3 and Flash Attention 2 to train these models in three hours using 32 A100-80GB GPUs, with a sequence length of 4096 tokens. > > Furthermore, we applied OpenAI's decontamination methodology to our dataset to ensure valid results, and found no contaminated examples. > > The methodology is: > > - For each evaluation example, we randomly sampled three substrings of 50 characters or used the entire example if it was fewer than 50 characters. > - A match was identified if any sampled substring was a substring of the processed training example. > > For further insights on the decontamination methodology, please refer to Appendix C of OpenAI's technical report. Presented below are the pass@1 scores we achieved with our fine-tuned models: > > - Phind-CodeLlama-34B-v1 achieved 67.6% pass@1 on HumanEval > - Phind-CodeLlama-34B-Python-v1 achieved 69.5% pass@1 on HumanEval > > ### Download > > We are releasing both models on Huggingface for verifiability and to bolster the open-source community. We welcome independent verification of results. > > - https://huggingface.co/Phind/Phind-CodeLlama-34B-v1 > - https://huggingface.co/Phind/Phind-CodeLlama-34B-Python-v1 > > --- > > If you get a chance to try either of these models out, let us know how it goes in the comments below! > > If you found anything about this post interesting, consider subscribing to !fosai@lemmy.world. > > Cheers to the power of open-source! May we continue the fight for optimization, efficiency, and performance.
cross-posted from: https://lemmy.world/post/3549390
> ## stable-diffusion.cpp
>
> Introducing stable-diffusion.cpp, a pure C/C++ inference engine for Stable Diffusion! This is a really awesome implementation to help speed up home inference of diffusion models.
>
> Tailored for developers and AI enthusiasts, this repository offers a high-performance solution for creating and manipulating images using various quantization techniques and accelerated inference.
>
> - https://github.com/leejet/stable-diffusion.cpp
>
> ---
>
> ### Key Features:
>
> - Efficient Implementation: Utilizing plain C/C++, it operates seamlessly like llama.cpp and is built on the ggml framework.
> - Multiple Precision Support: Choose between 16-bit, 32-bit float, and 4-bit to 8-bit integer quantization.
> - Optimized Performance: Experience memory-efficient CPU inference with AVX, AVX2, and AVX512 support for x86 architectures.
> - Versatile Modes: From original txt2img to img2img modes and negative prompt handling, customize your processing needs.
> - Cross-Platform Compatibility: Runs smoothly on Linux, Mac OS, and Windows.
>
> ---
>
> ### Getting Started
> Cloning, building, and running are made simple, and detailed examples are provided for both text-to-image and image-to-image generation. With an array of options for precision and comprehensive usage guidelines, you can easily adapt the code for your specific project requirements.
>
> > git clone --recursive https://github.com/leejet/stable-diffusion.cpp > cd stable-diffusion.cpp >
>
> - If you have already cloned the repository, you can use the following command to update the repository to the latest code.
>
> > cd stable-diffusion.cpp > git pull origin master > git submodule update >
>
> ---
>
> ### More Details
>
> - Plain C/C++ implementation based on ggml, working in the same way as llama.cpp
> - 16-bit, 32-bit float support
> - 4-bit, 5-bit and 8-bit integer quantization support
> - Accelerated memory-efficient CPU inference
> - Only requires ~2.3GB when using txt2img with fp16 precision to generate a 512x512 image
> - AVX, AVX2 and AVX512 support for x86 architectures
> - Original txt2img and img2img mode
> - Negative prompt
> - stable-diffusion-webui style tokenizer (not all the features, only token weighting for now)
> - Sampling method
> - Euler A
> - Supported platforms
> - Linux
> - Mac OS
> - Windows
>
> ---
>
> This is a really exciting repo. I'll be honest, I don't think I am as well versed in what's going on for diffusion inference - but I do know more efficient and effective methods running those models are always welcome by people frequently using diffusers. Especially for those who need to multi-task and maintain performance headroom.
cross-posted from: https://lemmy.world/post/3439370
> # Empowering Vision-Language Models to Follow Interleaved Vision-Language Instructions
>
> A wild new GitHub Repo has appeared!
> - https://github.com/DCDmllm/Cheetah/tree/main
>
> Today we cover Cheetah - an exciting new take on interleaving image and text context & instruction.
>
> For higher quality images, please visit the main projects repo to see their code and approach in all of their glory.
>
> ## I4 Benchmark
>
> To facilitate research in interleaved vision-language instruction following, we build I4 (semantically Interconnected, Interleaved Image-Text Instruction-Following), an extensive large-scale benchmark of 31 tasks with diverse instructions in a unified instruction-response format, covering 20 diverse scenarios.
>
> I4 has three important properties:
>
> - Interleaved vision-language context: all the instructions contain sequences of inter-related images and texts, such as storyboards with scripts, textbooks with diagrams.
> - Diverse forms of complex instructions: the instructions range from predicting dialogue for comics, to discovering differences between surveillance images, and to conversational embodied tasks.
> - Vast range of instruction-following scenarios: the benchmark covers multiple application scenarios, including cartoons, industrial images, driving recording, etc.
>
> !
>
> ## Cheetor: a multi-modal large language model empowered by controllable knowledge re-injection
> Cheetor is a Transformer-based multi-modal large language model empowered by controllable knowledge re-injection, which can effectively handle a wide variety of interleaved vision-language instructions.
>
> !
>
> ## Cases
> Cheetor demonstrates strong abilities to perform reasoning over complicated interleaved vision-language instructions. For instance, in (a), Cheetor is able to keenly identify the connections between the images and thereby infer the reason that causes this unusual phenomenon. In (b, c), Cheetor can reasonably infer the relations among the images and understand the metaphorical implications they want to convey. In (e, f), Cheetor exhibits the ability to comprehend absurd objects through multi-modal conversations with humans.
>
> !
>
> !
>
> ## Getting Started
> 1. Installation
>
> Git clone our repository and creating conda environment:
> bash > git clone https://github.com/DCDmllm/Cheetah.git > cd Cheetah/Cheetah > conda create -n cheetah python=3.8 > conda activate cheetah > pip install -r requirement.txt >
>
> 2. Prepare Vicuna Weights and Llama2 weights
>
> The current version of Cheetor supports Vicuna-7B and LLaMA2-7B as the language model. Please first follow the instructions to prepare Vicuna-v0 7B weights and follow the instructions to prepare LLaMA-2-Chat 7B weights.
>
> Then modify the llama_model in the Cheetah/cheetah/configs/models/cheetah_vicuna.yaml to the folder that contains Vicuna weights and modify the llama_model in the Cheetah/cheetah/configs/models/cheetah_llama2.yaml to the folder that contains LLaMA2 weights.
>
> 3. Prepare the pretrained checkpoint for Cheetor
>
> Download the pretrained checkpoints of Cheetah according to the language model you prepare:
> | Checkpoint Aligned with Vicuna 7B | Checkpoint Aligned with LLaMA2 7B |
> :------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------:
> Download | Download
>
> For the checkpoint aligned with Vicuna 7B, please set the path to the pretrained checkpoint in the evaluation config file in Cheetah/eval_configs/cheetah_eval_vicuna.yaml at Line 10.
>
> For the checkpoint aligned with LLaMA2 7B, please set the path to the pretrained checkpoint in the evaluation config file in Cheetah/eval_configs/cheetah_eval_llama2.yaml at Line 10.
>
> Besides, Cheetor reuses the pretrained Q-former from BLIP-2 that matches FlanT5-XXL.
>
> 4. How to use Cheetor
>
> Examples of using our Cheetah model are provided in files Cheetah/test_cheetah_vicuna.py and Cheetah/test_cheetah_llama2.py. You can test your own samples following the format shown in these two files. And you can run the test code in the following way (taking the Vicuna version of Cheetah as an example):
>
> > python test_cheetah_vicuna.py --cfg-path eval_configs/cheetah_eval_vicuna.yaml --gpu-id 0 >
>
> And in the near future, we will also demonstrate how to launch the gradio demo of Cheetor locally.
>
> ---
> ## ChatGPT-4 Breakdown:
>
> Imagine a brilliant detective who has a unique skill: they can understand stories told not just through spoken or written words, but also by examining pictures, diagrams, or comics. This detective doesn't just listen or read; they also observe and link the visual clues with the narrative. When given a comic strip without dialogues or a textbook diagram with some text, they can deduce what's happening, understanding both the pictures and words as one unified story.
>
> In the world of artificial intelligence, "Cheetor" is that detective. It's a sophisticated program designed to interpret and respond to a mix of images and texts, enabling it to perform tasks that require both vision and language understanding.
>
> Projects to Try with Cheetor:
>
> Comic Story Creator:
> Input: A series of related images or sketches.
> Cheetor’s Task: Predict and generate suitable dialogues or narratives to turn those images into a comic story.
>
> Education Assistant:
> Input: A page from a textbook containing both diagrams and some accompanying text.
> Cheetor’s Task: Answer questions based on the content, ensuring it considers both the visual and written information.
>
> Security Analyst:
> Input: Surveillance footage or images with accompanying notes or captions.
> Cheetor’s Task: Identify discrepancies or anomalies, integrating visual cues with textual information.
>
> Drive Safety Monitor:
> Input: Video snippets from a car's dashcam paired with audio transcriptions or notes.
> Cheetor’s Task: Predict potential hazards or traffic violations by understanding both the visual and textual data.
>
> Art Interpreter:
> Input: Art pieces or abstract images with associated artist's notes.
> Cheetor’s Task: Explain or interpret the art, merging the visual elements with the artist's intentions or story behind the work.
>
> ---
>
> This is a really interesting strategy and implementation! A model that can interpret both natural language text with high quality image recognition and computer vision can lead to all sorts of wild new applications. I am excited to see where this goes in the open-source community and how it develops the rest of this year.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
cross-posted from: https://lemmy.world/post/3439370
> # Empowering Vision-Language Models to Follow Interleaved Vision-Language Instructions
>
> A wild new GitHub Repo has appeared!
> - https://github.com/DCDmllm/Cheetah/tree/main
>
> Today we cover Cheetah - an exciting new take on interleaving image and text context & instruction.
>
> For higher quality images, please visit the main projects repo to see their code and approach in all of their glory.
>
> ## I4 Benchmark
>
> To facilitate research in interleaved vision-language instruction following, we build I4 (semantically Interconnected, Interleaved Image-Text Instruction-Following), an extensive large-scale benchmark of 31 tasks with diverse instructions in a unified instruction-response format, covering 20 diverse scenarios.
>
> I4 has three important properties:
>
> - Interleaved vision-language context: all the instructions contain sequences of inter-related images and texts, such as storyboards with scripts, textbooks with diagrams.
> - Diverse forms of complex instructions: the instructions range from predicting dialogue for comics, to discovering differences between surveillance images, and to conversational embodied tasks.
> - Vast range of instruction-following scenarios: the benchmark covers multiple application scenarios, including cartoons, industrial images, driving recording, etc.
>
> !
>
> ## Cheetor: a multi-modal large language model empowered by controllable knowledge re-injection
> Cheetor is a Transformer-based multi-modal large language model empowered by controllable knowledge re-injection, which can effectively handle a wide variety of interleaved vision-language instructions.
>
> !
>
> ## Cases
> Cheetor demonstrates strong abilities to perform reasoning over complicated interleaved vision-language instructions. For instance, in (a), Cheetor is able to keenly identify the connections between the images and thereby infer the reason that causes this unusual phenomenon. In (b, c), Cheetor can reasonably infer the relations among the images and understand the metaphorical implications they want to convey. In (e, f), Cheetor exhibits the ability to comprehend absurd objects through multi-modal conversations with humans.
>
> !
>
> !
>
> ## Getting Started
> 1. Installation
>
> Git clone our repository and creating conda environment:
> bash > git clone https://github.com/DCDmllm/Cheetah.git > cd Cheetah/Cheetah > conda create -n cheetah python=3.8 > conda activate cheetah > pip install -r requirement.txt >
>
> 2. Prepare Vicuna Weights and Llama2 weights
>
> The current version of Cheetor supports Vicuna-7B and LLaMA2-7B as the language model. Please first follow the instructions to prepare Vicuna-v0 7B weights and follow the instructions to prepare LLaMA-2-Chat 7B weights.
>
> Then modify the llama_model in the Cheetah/cheetah/configs/models/cheetah_vicuna.yaml to the folder that contains Vicuna weights and modify the llama_model in the Cheetah/cheetah/configs/models/cheetah_llama2.yaml to the folder that contains LLaMA2 weights.
>
> 3. Prepare the pretrained checkpoint for Cheetor
>
> Download the pretrained checkpoints of Cheetah according to the language model you prepare:
> | Checkpoint Aligned with Vicuna 7B | Checkpoint Aligned with LLaMA2 7B |
> :------------------------------------------------------------------------------------------------:|:----------------------------------------------------------------------------------------------:
> Download | Download
>
> For the checkpoint aligned with Vicuna 7B, please set the path to the pretrained checkpoint in the evaluation config file in Cheetah/eval_configs/cheetah_eval_vicuna.yaml at Line 10.
>
> For the checkpoint aligned with LLaMA2 7B, please set the path to the pretrained checkpoint in the evaluation config file in Cheetah/eval_configs/cheetah_eval_llama2.yaml at Line 10.
>
> Besides, Cheetor reuses the pretrained Q-former from BLIP-2 that matches FlanT5-XXL.
>
> 4. How to use Cheetor
>
> Examples of using our Cheetah model are provided in files Cheetah/test_cheetah_vicuna.py and Cheetah/test_cheetah_llama2.py. You can test your own samples following the format shown in these two files. And you can run the test code in the following way (taking the Vicuna version of Cheetah as an example):
>
> > python test_cheetah_vicuna.py --cfg-path eval_configs/cheetah_eval_vicuna.yaml --gpu-id 0 >
>
> And in the near future, we will also demonstrate how to launch the gradio demo of Cheetor locally.
>
> ---
> ## ChatGPT-4 Breakdown:
>
> Imagine a brilliant detective who has a unique skill: they can understand stories told not just through spoken or written words, but also by examining pictures, diagrams, or comics. This detective doesn't just listen or read; they also observe and link the visual clues with the narrative. When given a comic strip without dialogues or a textbook diagram with some text, they can deduce what's happening, understanding both the pictures and words as one unified story.
>
> In the world of artificial intelligence, "Cheetor" is that detective. It's a sophisticated program designed to interpret and respond to a mix of images and texts, enabling it to perform tasks that require both vision and language understanding.
>
> Projects to Try with Cheetor:
>
> Comic Story Creator:
> Input: A series of related images or sketches.
> Cheetor’s Task: Predict and generate suitable dialogues or narratives to turn those images into a comic story.
>
> Education Assistant:
> Input: A page from a textbook containing both diagrams and some accompanying text.
> Cheetor’s Task: Answer questions based on the content, ensuring it considers both the visual and written information.
>
> Security Analyst:
> Input: Surveillance footage or images with accompanying notes or captions.
> Cheetor’s Task: Identify discrepancies or anomalies, integrating visual cues with textual information.
>
> Drive Safety Monitor:
> Input: Video snippets from a car's dashcam paired with audio transcriptions or notes.
> Cheetor’s Task: Predict potential hazards or traffic violations by understanding both the visual and textual data.
>
> Art Interpreter:
> Input: Art pieces or abstract images with associated artist's notes.
> Cheetor’s Task: Explain or interpret the art, merging the visual elements with the artist's intentions or story behind the work.
>
> ---
>
> This is a really interesting strategy and implementation! A model that can interpret both natural language text with high quality image recognition and computer vision can lead to all sorts of wild new applications. I am excited to see where this goes in the open-source community and how it develops the rest of this year.
cross-posted from: https://lemmy.world/post/3350022
> Incognito Pilot: The Next-Gen AI Code Interpreter for Sensitive Data
>
> Hello everyone! Today marks the first day of a new series of posts featuring projects in my GitHub Stars.
>
> Most of these repos are FOSS & FOSAI focused, meaning they should be hackable, free, and (mostly) open-source.
>
> We're going to kick this series off by sharing Incognito Pilot. It’s like the ChatGPT Code Interpreter but for those who prioritize data privacy.
>
> !
>
> Project Summary from ChatGPT-4:
>
> Features:
>
> - Powered by Large Language Models like GPT-4 and Llama 2.
> - Run code and execute tasks with Python interpreter.
> - Privacy: Interacts with cloud but sensitive data stays local.
> - Local or Remote: Choose between local LLMs (like Llama 2) or API (like GPT-4) with data approval mechanism.
>
> You can use Incognito Pilot to:
>
> - Analyse data, create visualizations.
> - Convert files, e.g., video to gif.
> - Internet access for tasks like downloading data.
>
> Incognito Pilot ensures data privacy while leveraging GPT-4's capabilities.
>
> Getting Started:
>
> 1. Installation:
>
> - Use Docker (For Llama 2, check dedicated installation).
> - Create a folder for Incognito Pilot to access. Example: /home/user/ipilot.
> - Have an OpenAI account & API key.
> - Use the provided docker command to run.
> - Access via: http://localhost:3030
> - Bonus: Works with OpenAI's free trial credits (For GPT-3.5).
> 2. First Steps:
>
> - Chat with the interface: Start by saying "Hi".
> - Get familiar: Command it to print "Hello World".
> - Play around: Make it create a text file with numbers.
>
> Notes:
>
> - Data you enter and approved code results are sent to cloud APIs.
> - All data is processed locally.
> - Advanced users can customize Python interpreter packages for added functionalities.
>
> FAQs:
>
> - Comparison with ChatGPT Code Interpreter: Incognito Pilot offers a balance between privacy and functionality. It allows internet access, and can be run on powerful machines for larger tasks.
>
> - Why use Incognito Pilot over just ChatGPT: Multi-round code execution, tons of pre-installed dependencies, and a sandboxed environment.
>
> - Data Privacy with Cloud APIs: Your core data remains local. Only meta-data approved by you gets sent to the API, ensuring a controlled and conscious usage.
>
> ---
>
> Personally, my only concern using ChatGPT has always been about data privacy. This explores an interesting way to solve that while still getting the state of the art performance that OpenAI has managed to maintain (so far).
>
> I am all for these pro-privacy projects. I hope to see more emerge!
>
> If you get a chance to try this, let us know your experience in the comments below!
>
> ---
>
> Links from this Post
> - https://github.com/adynblaed?tab=stars
> - https://github.com/silvanmelchior/IncognitoPilot
>- Subscribe to !fosai@lemmy.world!
{kind=link}
cross-posted from: https://lemmy.world/post/3350022
> Incognito Pilot: The Next-Gen AI Code Interpreter for Sensitive Data
>
> Hello everyone! Today marks the first day of a new series of posts featuring projects in my GitHub Stars.
>
> Most of these repos are FOSS & FOSAI focused, meaning they should be hackable, free, and (mostly) open-source.
>
> We're going to kick this series off by sharing Incognito Pilot. It’s like the ChatGPT Code Interpreter but for those who prioritize data privacy.
>
> !
>
> Project Summary from ChatGPT-4:
>
> Features:
>
> - Powered by Large Language Models like GPT-4 and Llama 2.
> - Run code and execute tasks with Python interpreter.
> - Privacy: Interacts with cloud but sensitive data stays local.
> - Local or Remote: Choose between local LLMs (like Llama 2) or API (like GPT-4) with data approval mechanism.
>
> You can use Incognito Pilot to:
>
> - Analyse data, create visualizations.
> - Convert files, e.g., video to gif.
> - Internet access for tasks like downloading data.
>
> Incognito Pilot ensures data privacy while leveraging GPT-4's capabilities.
>
> Getting Started:
>
> 1. Installation:
>
> - Use Docker (For Llama 2, check dedicated installation).
> - Create a folder for Incognito Pilot to access. Example: /home/user/ipilot.
> - Have an OpenAI account & API key.
> - Use the provided docker command to run.
> - Access via: http://localhost:3030
> - Bonus: Works with OpenAI's free trial credits (For GPT-3.5).
> 2. First Steps:
>
> - Chat with the interface: Start by saying "Hi".
> - Get familiar: Command it to print "Hello World".
> - Play around: Make it create a text file with numbers.
>
> Notes:
>
> - Data you enter and approved code results are sent to cloud APIs.
> - All data is processed locally.
> - Advanced users can customize Python interpreter packages for added functionalities.
>
> FAQs:
>
> - Comparison with ChatGPT Code Interpreter: Incognito Pilot offers a balance between privacy and functionality. It allows internet access, and can be run on powerful machines for larger tasks.
>
> - Why use Incognito Pilot over just ChatGPT: Multi-round code execution, tons of pre-installed dependencies, and a sandboxed environment.
>
> - Data Privacy with Cloud APIs: Your core data remains local. Only meta-data approved by you gets sent to the API, ensuring a controlled and conscious usage.
>
> ---
>
> Personally, my only concern using ChatGPT has always been about data privacy. This explores an interesting way to solve that while still getting the state of the art performance that OpenAI has managed to maintain (so far).
>
> I am all for these pro-privacy projects. I hope to see more emerge!
>
> If you get a chance to try this, let us know your experience in the comments below!
>
> ---
>
> Links from this Post
> - https://github.com/adynblaed?tab=stars
> - https://github.com/silvanmelchior/IncognitoPilot
>- Subscribe to !fosai@lemmy.world!
I used to feel the same way until I found some very interesting performance results from 3B and 7B parameter models.
Granted, it wasn’t anything I’d deploy to production - but using the smaller models to prototype quick ideas is great before having to rent a gpu and spend time working with the bigger models.
Give a few models a try! You might be pleasantly surprised. There’s plenty to choose from too. You will get wildly different results depending on your use case and prompting approach.
Let us know if you end up finding one you like! I think it is only a matter of time before we’re running 40B+ parameters at home (casually).
Click Here to be Taken to the Megathread!
from !fosai@lemmy.world
> # Vicuna v1.5 Has Been Released! > > Shoutout to GissaMittJobb@lemmy.ml for catching this in an earlier post. > > Given Vicuna was a widely appreciated member of the original Llama series, it'll be exciting to see this model evolve and adapt with fresh datasets and new training and fine-tuning approaches. > > Feel free using this megathread to chat about Vicuna and any of your experiences with Vicuna v1.5! > > # Starting off with Vicuna v1.5 > > TheBloke is already sharing models! > > ## Vicuna v1.5 GPTQ > > ### 7B > - Vicuna-7B-v1.5-GPTQ > - Vicuna-7B-v1.5-16K-GPTQ > > ### 13B > - Vicuna-13B-v1.5-GPTQ > > --- > > ## Vicuna Model Card > > ### Model Details > > Vicuna is a chat assistant fine-tuned from Llama 2 on user-shared conversations collected from ShareGPT. > > #### Developed by: LMSYS > > - Model type: An auto-regressive language model based on the transformer architecture > - License: Llama 2 Community License Agreement > - Finetuned from model: Llama 2 > > #### Model Sources > > - Repository: https://github.com/lm-sys/FastChat > - Blog: https://lmsys.org/blog/2023-03-30-vicuna/ > - Paper: https://arxiv.org/abs/2306.05685 > - Demo: https://chat.lmsys.org/ > > #### Uses > > The primary use of Vicuna is for research on large language models and chatbots. The target userbase includes researchers and hobbyists interested in natural language processing, machine learning, and artificial intelligence. > > #### How to Get Started with the Model > > - Command line interface: https://github.com/lm-sys/FastChat#vicuna-weights > - APIs (OpenAI API, Huggingface API): https://github.com/lm-sys/FastChat/tree/main#api > > #### Training Details > > Vicuna v1.5 is fine-tuned from Llama 2 using supervised instruction. The model was trained on approximately 125K conversations from ShareGPT.com. > > For additional details, please refer to the "Training Details of Vicuna Models" section in the appendix of the linked paper. > > #### Evaluation Results > > !Vicuna Evaluation Results > > Vicuna is evaluated using standard benchmarks, human preferences, and LLM-as-a-judge. For more detailed results, please refer to the paper and leaderboard.
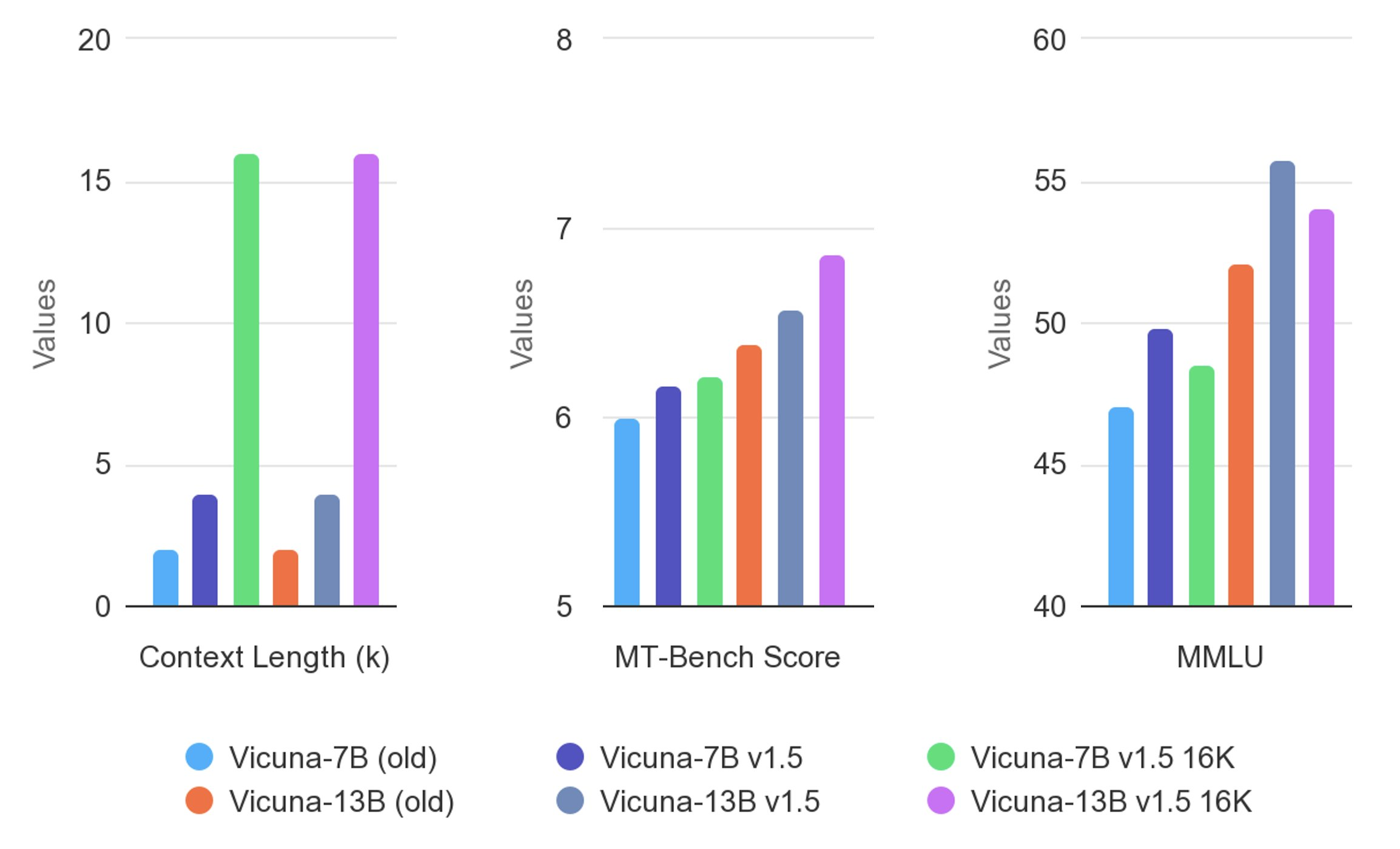{kind=link}
I am actively testing this out. It's hard to say at the moment. There's a lot to figure out deploying a model into a live environment, but I think there's real value in using them for technical tasks - especially as models mature and improve over time.
At the moment, though, performance is closer to GPT 3.5 than GPT 4, but I wouldn't be surprised if this is no longer the case within the next year or so.
After finally having a chance to test some of the new Llama-2 models, I think you're right. There's still some work to be done to get them tuned up... I'm going to dust off some of my notes and get a new index of those other popular gen-1 models out there later this week.
I'm very curious to try out some of these docker images, too. Thanks for sharing those! I'll check them when I can. I could also make a post about them if you feel like featuring some of your work. Just let me know!
Assuming everything from the papers translate into current platforms, yes! A rather significant one at that. Time will tell us the true results as people begin tinkering with this new approach in the near future.
Thanks for reading! I'm glad you enjoy the content. I find this tech beyond fascinating.
Who knows, over time you might even begin to pick up on some of the nuance you describe.
We're all learning this together!
Good bot, I will do that next time.
Come hangout with us at !fosai@lemmy.world
I run this show solo at the moment, but do my best to keep everyone informed. I have much more content on the horizon. Would love to have you if we have what you're looking for.
FOSAI Posts:
OpenAI has launched a new initiative, Superalignment, aimed at guiding and controlling ultra-intelligent AI systems. Recognizing the imminent arrival of AI that surpasses human intellect, the project will dedicate significant resources to ensure these advanced systems act in accordance with human intent. It's a crucial step in managing the transformative and potentially dangerous impact of superintelligent AI.
I like to think this starts to explore interesting philosophical questions like human intent, consciousness, and the projection of will into systems that are far beyond our capabilities in raw processing power and input/output. What may happen from this intended alignment is yet to be seen, but I think we can all agree the last thing we want in these emerging intelligent machines is to do things we don't want them to do.
'Superalignment' is OpenAI's response in how to put up these safeguards. Whether or not this is the best method is to be determined.
All of these are great thoughts and ponderings! Totally correct in the right circumstances, too.
Massive context lengths that can retain coherent memory and attention over long periods of time would enable all sorts of breakthroughs in LLM technology. At this point, you would be held back by performance, compute, and datasets, rather than LLM context windows and short-term memory. In this context, our focus would be towards optimizing attention or improving speed and accuracy.
Let's say you had hundreds of pages of a digital journal and felt like feeding this to a local LLM (where your data stays private). If the model was running sufficiently at high quality, you could have an AI assistant, coach, partner, or tutor that was caught up to speed with your project's goals, your personal aspirations, and your daily life within a matter of a few hours (or a few weeks, depending on hardware capabilities).
Missing areas of expertise you want your AI to have? Upload and feed it more datasets Matrix style, any text-based information that humanity has shared online is available to the model.
From here, you could further finetune and give your LLM a persona, having an assistant and personal operating system that breaks down your life with you, or you could simply 'chat' with your life, those pages you fed it, and reflect upon your thoughts and memories, tuned to a super intelligence beyond your own.
Poses some fascinating questions, doesn't it? About consciousness? Thought? You? This is the sort of stuff that keeps me up at night... If you trained a private LLM on your own notes, thoughts, reflections and introspection, wouldn't you be imposing a level of consciousness into a system far beyond your own mental capacities? I have already started to use LLMs on the daily. In the right conditions, I would absolutely utilize a tool like this. We're not at super intelligence yet, but an unlimited context window for a model of that caliber would be groundbreaking.
Information of any kind could be digitalized and formatted into datasets (at massive lengths), enabling this assistant or personal database to grow overtime with innovations of a project, you, your life, learning and discovering things alongside the intention and desire for it to function. At that point, we're starting to get into augmented human capabilities.
What this means over the course of many years and breakthroughs in models and training methods would be fascinating thought experiment to consider for a society where everyone is using massive context length LLMs regularly.
Sci-fi is quickly becoming a reality, how exciting! I'm here for it, that's for sure. Let's hope the technology stays free, and open and accessible for all of us to participate in its marvels.
You are correct in thinking this will demand a lot of compute. Hardware will need to scale to match these context lengths, but that is becoming increasingly possible with things like NVIDIA's Grace Hopper architecture and AMDs recent commitment to expanding their hardware selection for emerging AI markets and demand.
There are also some really interesting frameworks and hardware developments being made at TinyCorp & TinyGrad that aim to run these emerging technologies efficiently and accessibly. He talks about this in detail in his podcast with Lex Fridman, a great watch if you're interested in this sort of stuff.
It is an exciting time for technology and innovation. We have already started to hit exaflops of compute...
Great question. I ponder this too, which is why I started /c/FOSAI. We have to do everything we can to make sure our future stays open for all, our faith cannot be put into the hands of a select few, but rather - the majority of many.
Time will tell who truly supports this. I'm hopeful OpenAI is the good guy we want them to be, but other businesses keep me from jumping to that conclusion. I like what they are doing alongside Microsoft, but we need more players in the game. Fresh minds to shake things up a little.
If you're reading this, support FOSS, support FOSAI, and support the Fediverse. It's the only way we can take back the internet, one server at a time.
That's okay! I hope you find what you're looking for. If not, I'm sure someone will create a community for you soon. There's a lot of new users migrating, only a matter of time before more content starts filling up the empty spaces!
If you're interested in free, open-source artificial intelligence news, breakthroughs, and developments - you should head over and subscribe to /c/FOSAI. I'd love to have you! Say hi anytime. I do my best to avoid spam, sensationalism, and clickbait.