Machine Learning
- Researchers upend AI status quo by eliminating matrix multiplication in LLMsarstechnica.com Researchers upend AI status quo by eliminating matrix multiplication in LLMs
Running AI models without floating point matrix math could mean far less power consumption.

- Meta (Facebook) is sharing new research, models, and datasets from Meta FAIRai.meta.com Sharing new research, models, and datasets from Meta FAIR
Meta FAIR is releasing several new research artifacts. Our hope is that the research community can use them to innovate, explore, and discover new ways to apply AI at scale.

- Introducing Apple’s On-Device and Server Foundation Modelsmachinelearning.apple.com Introducing Apple’s On-Device and Server Foundation Models
At the 2024 Worldwide Developers Conference, we introduced Apple Intelligence, a personal intelligence system integrated deeply into…

- Let's reproduce GPT-2 (124M) | Andrej Karpathy | Jun 9, 2024
Video description: > We reproduce the GPT-2 (124M) from scratch. > >This video covers the whole process: > > First we build the GPT-2 network, then we optimize its training to be really fast, then we set up the training run following the GPT-2 and GPT-3 paper and their hyperparameters, then we hit run, and come back the next morning to see our results, and enjoy some amusing model generations. > > Keep in mind that in some places this video builds on the knowledge from earlier videos in the Zero to Hero Playlist (see my channel). You could also see this video as building my nanoGPT repo, which by the end is about 90% similar.
- A Few Useful Things to Know About Machine Learning | Tapping into the "folk knowledge" needed to advance machine learning | Pedro Domingos | Communications of the ACM | vol. 55 no. 10 | October 2012
Pedro Domingos summarizes 12 key lessons that machine learning researchers and practitioners have learned. These include pitfalls to avoid, important issues to focus on, and answers to common questions.
- Multicollinearity in Logistic Regression Models : Anesthesia & Analgesiajournals.lww.com Multicollinearity in Logistic Regression Models : Anesthesia & Analgesia
An abstract is unavailable.

Bayman, Emine Ozgur PhD*; Dexter, Franklin MD, PhD, FASA†. Multicollinearity in Logistic Regression Models. Anesthesia & Analgesia 133(2):p 362-365, August 2021. | DOI: 10.1213/ANE.0000000000005593
- [PLDI'23] Scallop: A Language for Neurosymbolic Programming
cross-posted from: https://lemmy.one/post/13942290
> Abstract: We present Scallop, a language which combines the benefits of deep learning and logical reasoning. Scallop enables users to write a wide range of neurosymbolic applications and train them in a data- and compute-efficient manner. It achieves these goals through three key features: 1) a flexible symbolic representation that is based on the relational data model; 2) a declarative logic programming language that is based on Datalog and supports recursion, aggregation, and negation; and 3) a framework for automatic and efficient differentiable reasoning that is based on the theory of provenance semirings. We evaluate Scallop on a suite of eight neurosymbolic applications from the literature. Our evaluation demonstrates that Scallop is capable of expressing algorithmic reasoning in diverse and challenging AI tasks, provides a succinct interface for machine learning programmers to integrate logical domain knowledge, and yields solutions that are comparable or superior to state-of-the-art models in terms of accuracy. Furthermore, Scallop's solutions outperform these models in aspects such as runtime and data efficiency, interpretability, and generalizability.
- Activation function and GLU variants for Transformer models | Tarique Anwar | Apr 18, 2022medium.com Activation function and GLU variants for Transformer models
Characterizing the first week of April 2022 as happening in the field of AI and Deep Learning would be an understatement. Within the same…
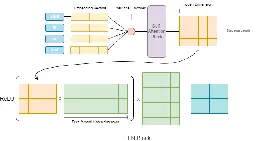
Apr 18, 2022 | Tarique Anwar Writes:
> The main reason for ReLu being used is that it is simple, fast, and empirically it seems to work well. > > But with the emergence of Transformer based models, different variants of activation functions and GLU have been experimented with and do seem to perform better. Some of them are: > > - GeLU² > - Swish¹ > - GLU³ > - GEGLU⁴ > - SwiGLU⁴ > > We will go over some of these in detail but before that let’s see where exactly are these activations utilized in a Transformer architecture.
Read Activation function and GLU variants for Transformer models
- Navigating Neural Networks: Exploring State-of-the-Art Activation Functions – OMSCS 7641: Machine Learning
> # Summary > Activation functions are crucial in neural networks, introducing non-linearity and enabling the modeling of complex patterns across varied tasks. This guide delves into the evolution, characteristics, and applications of state-of-the-art activation functions, illustrating their role in enhancing neural network performance. It discusses the transition from classic functions like sigmoid and tanh to advanced ones such as ReLU and its variants, addressing challenges like the vanishing gradient problem and the dying ReLU issue. Concluding with practical heuristics for selecting activation functions, the article emphasizes the importance of considering network architecture and task specifics, highlighting the rich diversity of activation functions available for optimizing neural network designs.
- Python Data Science Day will be taking place March 14th, 2024; a “PyDay” on Pi Daydevblogs.microsoft.com Data Science Day 2024 - Schedule Announcement - Python
Python Data Science Day will be taking place March 14th, 2024; a "PyDay" on Pi Day: 3.14 🥧. If you're a Python developer, entrepreneur, data scientist, student, or researcher working on projects from hobbyist and start up to enterprise level, you'll find solutions to modernize your data pipelines a...

Dawn Wages writes:
> Python Data Science Day is a full day of 25 min and 5 min community contributed content March 14th, 2024 streaming on the VS Code YouTube channel.
- Python Data Science Cloud Skills Challenge | Microsoft Learn
> Start 2024 with a new goal: become an expert with Python in the cloud. Join us this quarter as we challenge ourselves with Python, Machine Learning and Data Science. > > 7 hr 1 min | 10 Modules
- Midjourney bans all Stability AI employees over alleged data scrapingwww.theverge.com Midjourney bans all Stability AI employees over alleged data scraping
Midjourney claims the alleged activity caused a 24-hour service outage.

cross-posted from: https://lemmy.ml/post/13088944
- Image denoising techniques: A comparison of PCA, kernel PCA, autoencoder, and CNNwww.fabriziomusacchio.com Image denoising techniques: A comparison of PCA, kernel PCA, autoencoder, and CNN
In this post, we explore the performance of PCA, Kernel PCA, denoising autoencoder, and CNN for image denoising.

June 21, 2023 | Fabrizio Musacchio writes:
> In this post, we will explore the potential of PCA [Principal Component Analysis], denoising autoencoders and Convolutional Neural Networks (CNN) for restoring noisy images using Python. We will examine their performance, advantages, and disadvantages to determine the most effective method for image denoising.
- Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealingwww.research.autodesk.com Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing
Why graphical representation and visualization are so important to...
The code https://github.com/jmatejka/same-stats-different-graphs
- Opus 1.5 Released - achieves audible, non-stuttering talk at 90% packet loss
cross-posted from: https://programming.dev/post/11034601
There's a lot, and specifically a lot of machine learning talk and features in the 1.5 release of Opus - the free and open audio codec.
Audible and continuous (albeit jittery) talk on 90% packet loss is crazy.
Section WebRTC Integration → Samples has an example where you can test out the 90 % packet loss audio.
- Where Is Noether's Principle in Machine Learning? | 2024-02-29
2024-02-29 | Christopher Gadzinski writes:
> Physics likes optimization! Subject to its boundary conditions, the time evolution of a physical system is a critical point for a quantity called an action. This point of view sets the stage for Noether's principle, a remarkable correspondence between continuous invariances of the action and conservation laws of the system. > > In machine learning, we often deal with discrete "processes" whose control parameters are chosen to minimize some quantity. For example, we can see a deep residual network as a process where the role of "time" is played by depth. We may ask: > > 1. Does Noether's theorem apply to these processes? > 2. Can we find meaningful conserved quantities? > > Our answers: "yes," and "not sure!"
- Why Is the Current XAI Not Meeting the Expectations? – Communications of the ACM
XAI = Explainable Artificial Intelligence
Dec 14 2023
Alessio Malizia and Fabio Paternò write:
> Numerous papers argue for using XAI methods in the literature, as well as multiple suggestions for brand-new XAI family approaches. Nevertheless, finding instances of practical XAI technique implementations that have enhanced the business in industry/societal/real-world applications is more challenging, even if some interesting work in this area has been put forward, for example in the health domain
- A One-Stop Shop for Principal Component Analysistowardsdatascience.com A One-Stop Shop for Principal Component Analysis
At the beginning of the textbook I used for my graduate stat theory class, the authors (George Casella and Roger Berger) explained in the…
Apr 17, 2017 Matt Brems writes:
> Principal component analysis (PCA) is an important technique to understand in the fields of statistics and data science… but when putting a lesson together for my General Assembly students, I found that the resources online were too technical, didn’t fully address our needs, and/or provided conflicting information. It’s safe to say that I’m not “entirely satisfied with the available texts” here. > > As a result, I wanted to put together the “What,” “When,” “How,” and “Why” of PCA as well as links to some of the resources that can help to further explain this topic. Specifically, I want to present the rationale for this method, the math under the hood, some best practices, and potential drawbacks to the method. > > While I want to make PCA as accessible as possible, the algorithm we’ll cover is pretty technical. Being familiar with some or all of the following will make this article and PCA as a method easier to understand: matrix operations/linear algebra (matrix multiplication, matrix transposition, matrix inverses, matrix decomposition, eigenvectors/eigenvalues) and statistics/machine learning (standardization, variance, covariance, independence, linear regression, feature selection). I’ve embedded links to illustrations of these topics throughout the article, but hopefully these will serve as a reminder rather than required reading to get through the article.
- Spark vs Presto: A Comprehensive Comparisonwww.analyticsvidhya.com Spark vs Presto: A Comprehensive Comparison
Here is the comparison of Spark vs Presto in big data processing. Understand the nuances to make informed choice in data analytics journey.
cross-posted from: https://programming.dev/post/9436800
> December 28 2023 Pankaj Singh writes: > > > In big data processing and analytics, choosing the right tool is paramount for efficiently extracting meaningful insights from vast datasets. Two popular frameworks that have gained significant traction in the industry are Apache Spark and Presto. Both are designed to handle large-scale data processing efficiently, yet they have distinct features and use cases. As organizations grapple with the complexities of handling massive volumes of data, a comprehensive understanding of Spark and Presto’s nuances and distinctive features becomes essential. In this article, we will compare Spark vs Presto, exploring their performance and scalability, data processing capabilities, ecosystem, integration, and use cases and applications. > > Read Spark vs Presto: A Comprehensive Comparison
- Offline listening and speaking botgithub.com GitHub - nydasco/jen-ai: A simple speech-to-text and text-to-speech AI chatbot that can be run fully offline.
A simple speech-to-text and text-to-speech AI chatbot that can be run fully offline. - GitHub - nydasco/jen-ai: A simple speech-to-text and text-to-speech AI chatbot that can be run fully offline.

cross-posted from: https://lemmy.world/post/11196216
> Hi all, > > For those wanting a quick repo to use as a basis to get started, I’ve created jen-ai. > > There are full instructions in the readme. Once running you can talk to it, and it will respond. > > It’s basic, but a place to start.
- My Target Audience | The Two Culture Problemscientificcoder.com My Target Audience
What kind of people do I have in mind while writing this blog? People who share my professional mission of course! What is that mission you ask? Let me elaborate. From Research to Engineering I am a scientist who danced with startups and moved into i...
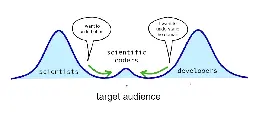
cross-posted from: https://programming.dev/post/9428234
> Apr 18, 2023 Matthijs Cox writes: > > > The “two language problem” was globally accepted for several decades. You just learn to live with it. Until one day it was challenged by the Julia language, a programming language that promises both speed and ease of use. As I feel the pain of the two language problem deeply, I wanted to try out this new solution. So together with several allies I went on a mission to adopt this new technology at work, and remove the bottleneck. > > > > While we had initial success and attention, we quickly stumbled into resistance from the existing groups of researchers/scientists and developers. Over time I have named this the “two culture problem”. In the beginning I didn’t see the cultures clearly, which limited our success. I was too focused on the technological problem itself. > > > > I will refer to the two cultures as “scientists” versus “developers”. However, the “scientists” group generalizes to anyone who codes quick and dirty to explore, such as domain experts, data analysts and others like that. I do hope everyone is doing their exploration somewhat scientifically, so the generalization should makes sense. Scientists typically want to get their stuff done, perhaps with code, but they don't care about the code. Software developers care deeply about the code craftsmanship, sometimes obsessively so, but often developers barely understand the business domain or science. There are people near the middle, trying to balance both, but they are a rare breed. > > Read My Target Audience
- The Math behind Adam Optimizer | Towards Data Sciencetowardsdatascience.com The Math behind Adam Optimizer
Why is Adam the most popular optimizer in Deep Learning? Let’s understand it by diving into its math, and recreating the algorithm.

The article discusses the Adam optimizer, a popular algorithm in deep learning known for its efficiency in adjusting learning rates for different parameters.
Unlike other optimizers like SGD or Adagrad, Adam dynamically changes its step size based on the complexity of the problem, analogous to adjusting stride in varying terrains. This ability to adapt makes it effective in quickly finding the minimum loss in machine learning tasks, a key reason for its popularity in winning Kaggle competitions and among those seeking a deeper understanding of optimizer mechanics.
- Code Llama 70B: a new, more performant version of Meta's LLM for code generation is now available.
> Today we’re releasing Code Llama 70B: a new, more performant version of our LLM for code generation — available under the same license as previous Code Llama models. > > Download the models > - CodeLlama-70B > - CodeLlama-70B-Python > - CodeLlama-70B-Instruct > > CodeLlama-70B-Instruct achieves 67.8 on HumanEval, making it one of the highest performing open models available today. > > CodeLlama-70B is the most performant base for fine-tuning code generation models and we’re excited for the community to build on this work.
- Real World Data Science Competition | When will the cherry trees bloom?realworlddatascience.net Real World Data Science - When will the cherry trees bloom? Get ready to make and share your predictions!
The 2024 International Cherry Blossom Prediction Competition will open for entries on February 1. There’s cash and prizes on offer for the best entries, including having your work featured on Real World Data Science.

Real World Data Science Writes:
> The 2024 International Cherry Blossom Prediction Competition will open for entries on February 1, and Real World Data Science is once again proud to be a sponsor. > > Contestants are invited to submit predictions for the date cherry trees will bloom in 2024 at five different locations – Kyoto, Japan; Liestal-Weideli, Switzerland; Vancouver, Canada; and Washington, DC and New York City, USA.
Read details about Real World Data Science Competition | When will the cherry trees bloom?
- NumPy 2 is coming: preventing breakage, updating your codepythonspeed.com NumPy 2 is coming: preventing breakage, updating your code
NumPy 2 is coming, and it’s backwards incompatible. Learn how to keep your code from breaking, and how to upgrade.

cross-posted from: https://programming.dev/post/8724281
> Itamar Turner-Trauring writes: > > > These sort of problems are one of the many reasons you want to “pin” your application’s dependencies: make sure you only install a specific, fixed set of dependencies. Without reproducible dependencies, as soon as NumPy 2 comes out your application might break when it gets installed with new dependencies. > > > > The really short version is that you have two sets of dependency configurations: > > > > - A direct dependency list: A list of libraries you directly import in your code, loosely restricted. This is the list of dependencies you put in pyproject.toml or setup.py. > > - A lock file: A list of all dependencies you rely on, direct or indirect (dependencies of dependencies), pinned to specific versions. This might be a requirements.txt, or some other file dependencies on which tool you’re using. > > > > At appropriate intervals you update the lock file based on the direct dependency list. > > > > I’ve written multiple articles on the topic, in case you’re not familiar with the relevant tools: > > > > - “Faster Docker builds with pipenv, poetry, or pip-tools” covers using those three tools to maintain lockfiles. > > - For Conda, see “Reproducible and upgradable Conda environments with conda-lock”. > > Read NumPy 2 is coming: preventing breakage, updating your code
- The Random Transformer | Understand how transformers work by demystifying all the math behind themosanseviero.github.io hackerllama - The Random Transformer
Understand how transformers work by demystifying all the math behind them
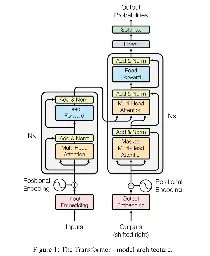
January 1, 2024 - Omar Sanseviero writes:
> In this blog post, we’ll do an end-to-end example of the math within a transformer model. The goal is to get a good understanding of how the model works. To make this manageable, we’ll do lots of simplification. As we’ll be doing quite a bit of the math by hand, we’ll reduce the dimensions of the model. For example, rather than using embeddings of 512 values, we’ll use embeddings of 4 values. This will make the math easier to follow! We’ll use random vectors and matrices, but you can use your own values if you want to follow along.
Read The Random Transformer | Understand how transformers work by demystifying all the math behind them
- GPU-based ODE solvers which are 20x-100x faster than those in #jax and #pytorch
cross-posted from: https://programming.dev/post/8391233
> Dr. Chris Rackauckas > (@chrisrackauckas@fosstodon.org) writes: > > > #julialang GPU-based ODE solvers which are 20x-100x faster than those in #jax and #pytorch? Check out the paper on how #sciml DiffEqGPU.jl works. Instead of relying on high level array intrinsics that #machinelearning libraries use, it uses a direct kernel generation approach to greatly reduce the overhead. > > Read Automated translation and accelerated solving of differential equations on multiple GPU platforms
- Linear Algebra Done Right 4th ed being released as CC BY-NC | Free PDF Link in the Post
Sheldon Axler Writes:
> I am happy to announce publication of the fourth edition of Linear Algebra Done Right as an Open Access book. The electronic version of this new fourth edition with a Creative Commons BY-NC license is availble without cost at the link below. > > - PDF file for Linear Algebra Done Right, fourth edition > > The print version of the new fourth edition of Linear Algebra Done Right is now available from Amazon and from Springer at the links below. > > - Amazon: print version of Linear Algebra Done Right, fourth edition > - Springer: print version of Linear Algebra Done Right, fourth edition > > The fourth edition of Linear Algebra Done Right contains over 250 new exercises and over 70 new examples, along with several new topics and multiple improvements throughout the book. See page xvi in the file linked above for a list of major improvements and additions in the fourth edition. > > This best-selling textbook for a second course in linear algebra is aimed at undergraduate math majors and graduate students. The novel approach taken here banishes determinants to the end of the book. The text focuses on the central goal of linear algebra: understanding the structure of linear operators on finite-dimensional vector spaces. The author has taken unusual care to motivate concepts and to simplify proofs. A variety of interesting exercises in each chapter helps students understand and manipulate the objects of linear algebra. > > No prerequisites are assumed other than the usual demand for suitable mathematical maturity. Thus the text starts by discussing vector spaces, linear independence, span, basis, and dimension. The book then deals with linear maps, eigenvalues, and eigenvectors. Inner product spaces are then introduced, leading to the finite-dimensional spectral theorem and its consequences such as the singular value decomposition. Generalized eigenvectors are then used to provide insight into the structure of a linear operator. Determinants are cleanly introduced via alternating multilinear forms.
- Sentence Embeddings | Everything you wanted to know about sentence embeddings (and maybe a bit more)osanseviero.github.io hackerllama - Sentence Embeddings
Everything you wanted to know about sentence embeddings (and maybe a bit more)
January 7, 2024 by Omar Sanseviero:
> This series aims to demystify embeddings and show you how to use them in your projects. This first blog post will teach you how to use and scale up open-source embedding models. We’ll look into the criteria for picking an existing model, current evaluation methods, and the state of the ecosystem. We’ll look into three exciting applications: > > - Finding the most similar Quora or StackOverflow questions > - Given a huge dataset, find the most similar items > - Running search embedding models directly in the users’ browser (no server required) > > You can either read the content here or execute it in Google Colab by clicking the badge at the top of the page. Let’s dive into embeddings!
Read Sentence Embeddings | Everything you wanted to know about sentence embeddings (and maybe a bit more)
- Python Rgonomics | Emily Riedereremilyriederer.netlify.app Python Rgonomics | Emily Riederer
Switching languages is about switching mindsets - not just syntax. New developments in python data science toolings, like polars and seaborn’s object interface, can capture the ‘feel’ that converts from R/tidyverse love while opening the door to truly pythonic workflows
> Switching languages is about switching mindsets - not just syntax. New developments in python data science toolings, like polars and seaborn’s object interface, can capture the ‘feel’ that converts from R/tidyverse love while opening the door to truly pythonic workflows
> Just to be clear: > > - This is not a post about why python is better than R so R users should switch all their work to python > - This is not a post about why R is better than python so R semantics and conventions should be forced into python > - This is not a post about why python users are better than R users so R users need coddling > - This is not a post about why R users are better than python users and have superior tastes for their toolkit > - This is not a post about why these python tools are the only good tools and others are bad tools
> # The Stack > > WIth that preamble out of the way, below are a few recommendations for the most ergonomic tools for getting set up, conducting core data analysis, and communication results. > > To preview these recommendations: > > ### Set Up > > Installation: pyenv > IDE: VS Code > > ### Analysis > > Wrangling: polars > Visualization: seaborn > > ### Communication > > Tables: Great Tables > Notebooks: Quarto > > ### Miscellaneous > > Environment Management: pdm > Code Quality: ruff
Read Python Rgonomics
- Data Science Better Practices, Part 2 — Work Togethertowardsdatascience.com Data Science Better Practices, Part 2 — Work Together
You can’t just throw more data scientists at this model and expect the accuracy to magically increase.

cross-posted from: https://programming.dev/post/8246313
> Data science managers and leaders should make sure that cooperative work on models is facilitated and streamlined. In this post, our very own Shachaf Poran, PhD suggests one method of doing so.
- Transformer-Based Large Language Models Are Not General Learners: A Universal Circuit Perspective
For folks who aren't sure how to interpret this, what we're looking at here is early work establishing an upper bound on the complexity of a problem that a model can handle based on its size. Research like this is absolutely essential for determining whether these absurdly large models are actually going to achieve the results people have already ascribed to them on any sort of consistent basis. Previous work on monosemanticity and superposition are relevant here, particularly with regards to unpacking where and when these errors will occur.
I've been thinking about this a lot with regards to how poorly defined the output space they're trying to achieve is. Currently we're trying to encode one or more human languages, logical/spatial reasoning (particularly for multimodal models), a variety of writing styles, and some set of arbitrary facts (to say nothing of the nuance associated with these facts). Just by making an informal order of magnitude argument I think we can quickly determine that a lot of the supposed capabilities of these massive models have strict theoretical limitations on their correctness.
This should, however, give one hope for more specialized models. Nearly every one of the above mentioned "skills" is small enough to fit into our largest models with absolute correctness. Where things get tough is when you fail to clearly define your output space and focus training so as to maximize the encoding efficiency for a given number of parameters.
- Do Users Write More Insecure Code with AI Assistants?chaos.social ~n (@nblr@chaos.social)
This is fine... "We observed that participants who had access to the AI assistant were more likely to introduce security vulnerabilities for the majority of programming tasks, yet were also more likely to rate their insecure answers as secure compared to those in our control group." https://arxiv.o...
~n (@nblr@chaos.social) writes:
>This is fine... >>"We observed that participants who had access to the AI assistant were more likely to introduce security vulnerabilities for the majority of programming tasks, yet were also more likely to rate their insecure answers as secure compared to those in our control group." > >[Do Users Write More Insecure Code with AI Assistants?](https://arxiv.org/abs/2211.03622?

