You're viewing a single thread.
https://join-lemmy.org/docs/contributors/07-ranking-algo.html is everything you need
To summarize it for people that don't feel like clicking the link, it essentially takes the log of the post score and then divides it by an exponential function of the time since the post was published.
And this picture helps too: shows the decay in ranking scores for posts of different popularity (score) over time.
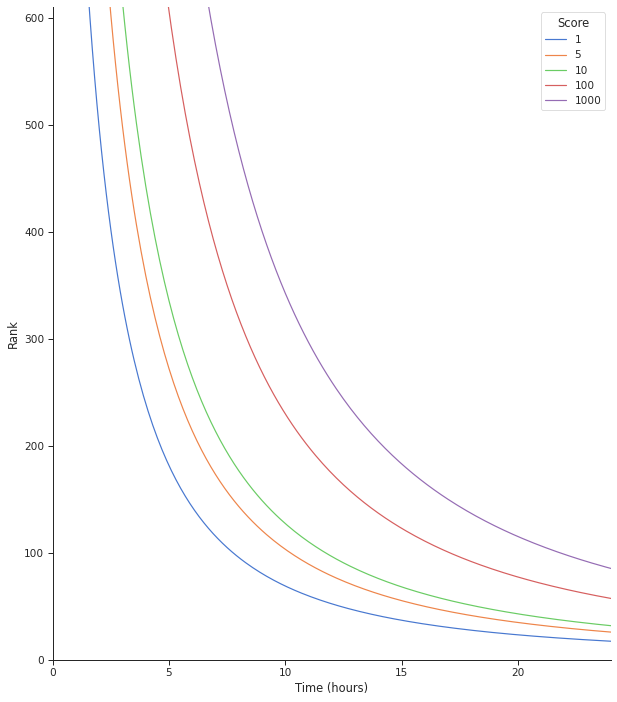
After a day or so, the curve flattens out. This probably explains why we keep seeing posts that are months old in "hot" - if not enough new material is being posted, after the first few pages of "hot", posts that are 5 days old and 5 months old are essentially the same due to the exponential decay function that was chosen.
That page gives this equation:
Rank = ScaleFactor * log(Max(1, 3 + Score)) / (Time + 2)^Gravity Score = Upvotes - Downvotes Time = time since submission (in hours) Gravity = Decay gravity, 1.8 is defaultMy guess is that the "gravity" parameter is the issue at the moment. Something is needed to make the decay less steep, so that really old posts aren't making it up to the top of the feed.
There might be some way of tuning the gravity parameter dynamically based on how much content is being submitted, perhaps aiming for something like "the average age of the first 200 posts should be 10 days" (I made those numbers up, but the basic idea would be that the time decay should be steeper when lots of content is submitted and less steep when content is infrequent?)
I know some of those words.
Permanently Deleted
don't worry, its already fixed. should be in the next release.
On my personal instance I'm running a build with that and its properly giving nice recent posts ( including the OP)
After all of this, I will amend my response to say that I think that there must be something going wrong with the algorithm. Consider these two consecutive posts on my "hot" feed:
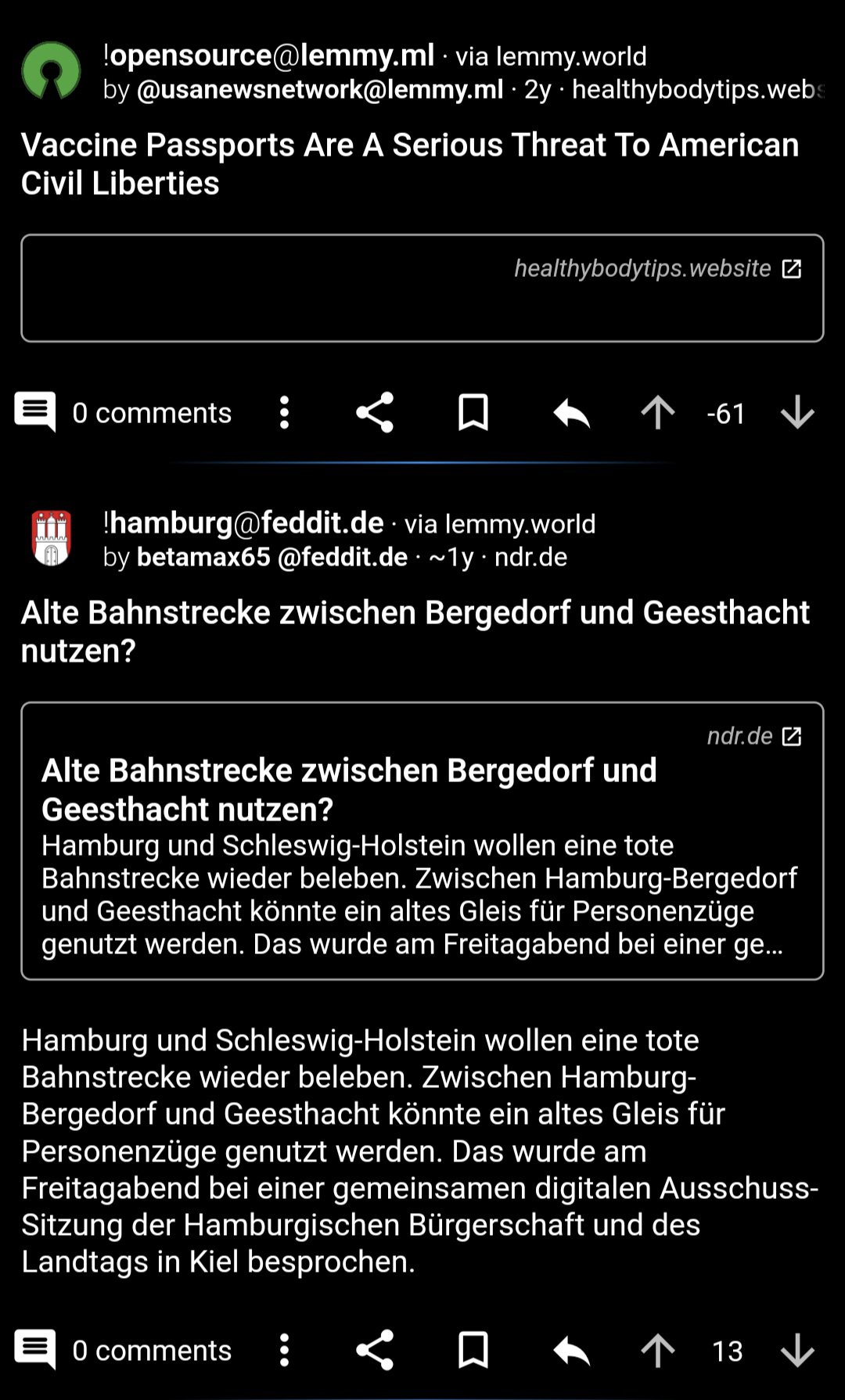
The anti-vax nonsense from two years ago was appropriately downvoted to hell. The post right underneath it is one year old and has a post score of +13. Based on the equation above, the lower post must have a higher rank than the anti-vax post, as it should have both a higher numerator and a lower denominator.
Time for a review of the source code? Or am I missing something? Do other people see this phenomenon? No older, lower-scored post should be above a newer and higher-scored post in your feed, I think.
After a year, both have basically the same rank = 0
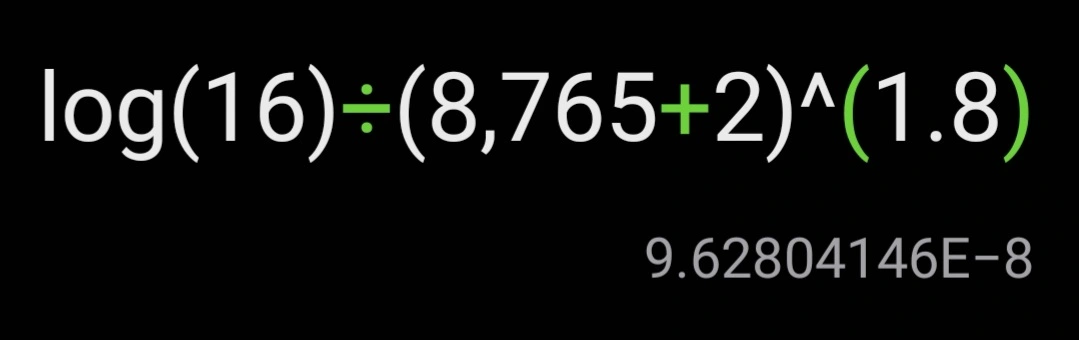
8765 hours in a year, growing exponentially, while the score is static and growns in log.
Yeah - though I had thought that still the one should be higher than the other, even if the numbers are small. In the actual equation, this would be multiplied by a scaling factor of 10000, though. (See the code discussion in the other comments). Though, in this case, the rank would still be very close to zero.
What I had missed is that, in the actual code, the equation is wrapped in
floor()and returns an integer. So both are treated as rank = 0 and maybe randomly sorted.The question is why are rank 0 posts showing up at all? Any other comment, I think if you do the math, it should take quite a bit of time for any post with an appreciable score to decay to a rank of zero. Yet we see that these sorts of old posts are appearing relatively high in the hot feed.
One possible answer was suggested in another comment -- it may have to do with how often the scores are recalculated for older posts, and if some have not decayed to zero by the time that the score recalculation stops, they might persist with a non zero score until the instance is restarted. I'm still not sure that that is the right answer, however, because I am guessing that instances like lemmy.world (which I am using) have been restarted recently with the various hacking attempts?
Didn't knew the value of the scaling factor, but supposed it didn't mattered a lot when the denominator of the division is in the 10^(-8) range.
Another problem in my opinion is in the log(max(1,3+score)), anything with a score of -2 or less send the max function to 1, the log(1) to 0 and the whole score to 0, so the distributions of post with score 0 should be gigantic without discrimination of a controversial - something score post against something with a score of - thousands. Also, some malicious agent can just use 3 bots to totally fuck all the post on new.
I don't think the max(1, 3 + score) work well neither, basically a post with a score of -2 and another of -100 have have the same log(1) = 0 rank.
So who can change the algorithm? Is it up to the admins of each instance (lemmy.world in my case) to change the numbers? There's not a centralized formula that each instance refers to is there?
Technically every admin could change it by making the change to the code and recompiling it. Practically it's just code contributors to lemmy development.
Damn. So comments are not included. Anything that has a crapton of comments yet is controversial won't be shown despite being hot.
To my understanding that's what "active" is for
Well it's doing a pretty shabby job then innit?
Yes,
Activeis basicallyHotbut comments are included in the equation.
Very nice analysis.
Maybe you want a more neutral and stable metrics for a dynamic measure of the gravity? Otherwise you can flood Lemmy with new posts to bury something.
Maybe something related to the average number of active users over the past 30 days over the topics you are looking at, which is harder to alter. But regardless, the steepness is definitely an issue as it should change with the number of posts.
Yeah - agreed. I don't know the best solution. The other issue is whether the algorithm is being applied to all feeds and communities in the same way. The experience will be quite different if browsing all on a highly federated, high activity instance, compared to just looking at your subscriptions or browsing a lower-activity single community. Maybe the answer is just in general to decrease the steepness of the curve.
thanks for the explanation! I wonder whether it is possible, or rather scalable, if users can pick their own parameters, even define their own functions. Is this calculated and cached at the server side or user side?
I understand some of the words you said. Sounds like you are the person to fix it 😁.
Thank you.
Thanks 😊
And the relevant source code
And this is a great thing about open source software
Want to know how something works? Want to know the implications of something, or whether it is artificially manipulated? You can go directly to the code.
How does the algorithm work for other software, and is it authentic and not manipulated for other gains? Nobody knows except them, and bad stuff can be hidden away.
Can someone who knows PL/pgSQL help parse this line:
return floor(10000*log(greatest(1,score+3)) / power(((EXTRACT(EPOCH FROM (timezone('utc',now()) - published))/3600) + 2), 1.8))::integer;It seems to me that the issue might be that the function returns an integer. If the scaling factor is inadequately large, then
floor()would return zero for tons of posts (any post where the equation insidefloor()evaluates to less than one). All of those posts would have equivalent ranks. This could explain why we start seeing randomly sorted old posts after a certain score threshold. Maybe better not to round here or dramatically increase the scaling factor?I'm not sure what the units of the post age would be in here, though. Probably hours based on the division by 3600? And is
log()the natural log or base 10 by default?In any case, something still must be going wrong. If I'm doing the math correctly, a post with a score of +25 should take approximately 203 hours (assuming log base 10) before it reaches a raw rank score of < 1 and gets floored to zero. So we should be seeing all posts from the last 8.5 days that had +25 scores before we see any of these really old posts... But that isn't what's happening.
Just curious, is this something that admins of individual instances could adjust for themselves? I could see some specialized instances being able to make use of a customized sorting algorithm for this.
If this is something that admins can adjust, does that impact anything with that content shared to or accessed from any federated instances?
I don't think any of the algorithm is expose to other instances so that wouldn't impact the communication between instances. At the end of the day this is open source so admins can freely build a forked version of Lemmy with a slightly different algorithm.