I'm in Twubble 🫨
I'm in Twubble 🫨
Edit: Update 2024-10-30
Let it be known that Mr. Alexandru was very patient with me and resolved everything for me by upgrading his infrastructure a few days later. I really appreciate it!


TankieTube is suffering from success.
Tankietube must now do degrowth, confirmed thirdworldist site

Did you buy hosting from some person trying to do a startup in their college dorm?
Ngl, I read the header "Dear Tankie" and it got my hackles up having read his email as passive aggressive, thought he clocked you're politics and was being a shitty mod about it, but then reading further it turns out it's your username and he seems chill lmao
Hope y'all can sort this out
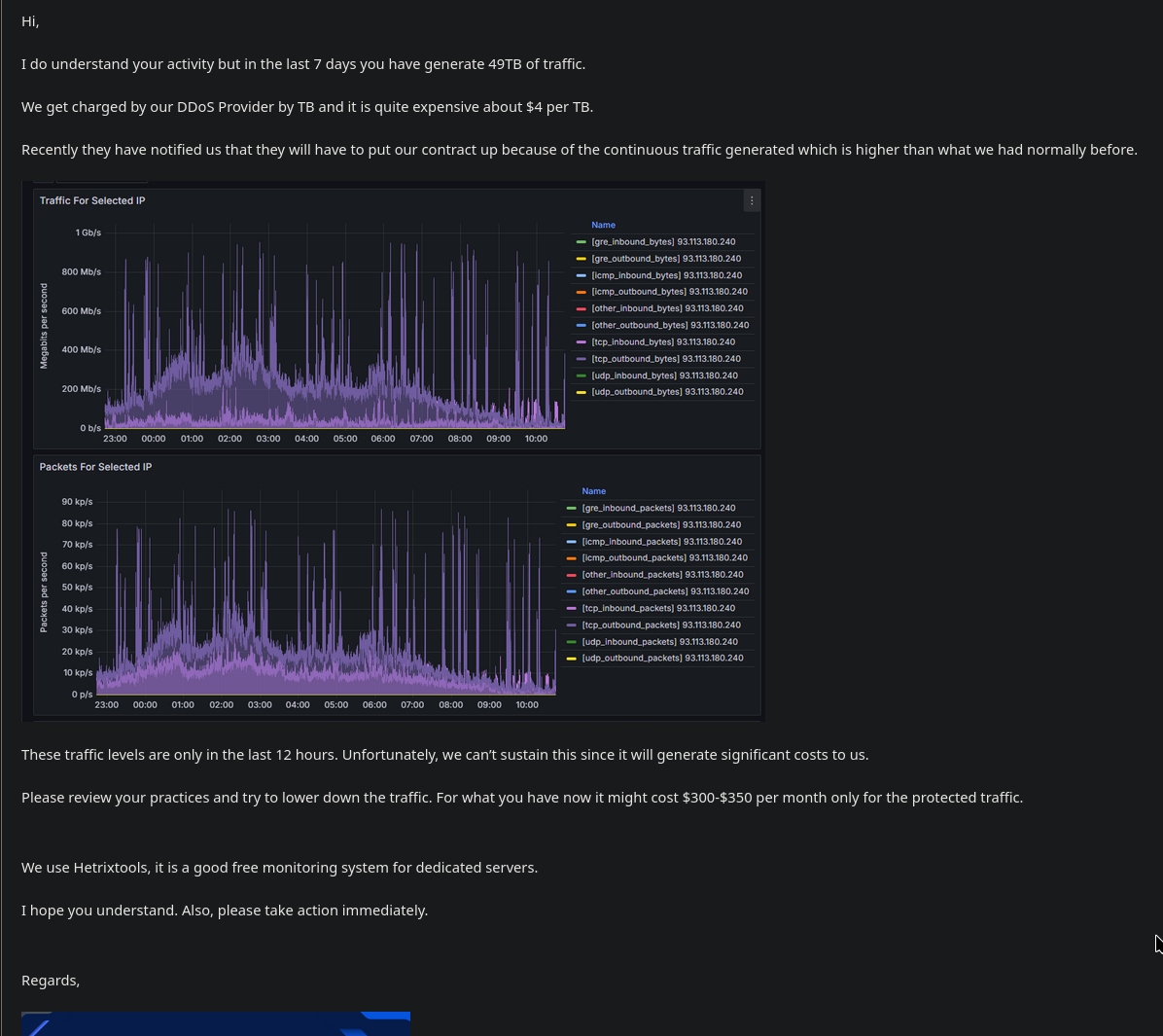
Dear Tankie, can you stop uploading that 4k video of 911 with the text "JDPON unlimited genocide on the United SSnake$ of AmeriKKKa" over and over again on my server?
- While we offer unlimited bandwidth and space to our customers we reserve the right to request that you delete excessive file such as large logs or anything else we deem excessive. Any uploaded files that cause the server to lag or make the server unplayable are not the responsibility of FREAKHOSTING.
Things like this scream red flags in my eyes, they'd rather use a more preferable term for marketing and hide arbitrary limitations in their acceptable use policy that most people aren't going to read rather than just sell you a product with limitations upfront (something like a 30TB/month bandwidth cap with no restrictions which is pretty standard for dedicated hardware of this price)
Unlimited bandwidth1.
1 Limits apply. No, we will not tell you what they are.
Ya this is kinda why youtube is the only game in town for video hosting on that scale. There is a huge entry cost to start a service like that. The amount of traffic video streaming generates is just crazy. Not really comparable to something like lemmy which is mostly text. and even the pictures here load kinda slow lol. Not that im complaining just pointing out that video hosting is a whole other beast.
Deeply unserious hosting company, "we're poor uwu beans"
The company seems to be a one man operation and I'd feel bad if I bankrupted him tbh.
I know it's all just business, but it hits me at an interpersonal level.
How much of this is between TankieTube and end users / peer instances vs. back and forth between TankieTube and the object storage provider? I don't know how they're measuring this, but if they are combining upload and download together as "traffic," then you are getting dinged twice for every video TT proxies (download from object storage, upload to end user - and traffic between data centers can rack up FAST). If a lot of round trips are being made between TT and the object storage provider, you might be able to alleviate this somewhat with caching (requiring more local disks) on the instance. Ideally, you should cache as much video as possible on the main server granting whatever headroom is needed for postgres etc. and fetch from object storage only on a cache miss.
Alternately, depending on the object storage provider, it might be possible for end users to download the media directly from them (using HTTP redirects or a CNAME record), but object storage usually meters bandwidth and charges for it (may be preferable to getting shut down, but also may be EXPENSIVE depending on the host).
If none of this is sufficient, you might need to look into load balancing / CDN. I know jack shit about this though, I just run a Mastodon instance and keep any media requested from object storage cached on the VPS for 7 days. It does not make optimal use of the disk, but it is sufficient for the use case (MUCH smaller media files, and heavily biased by the user interface towards recent posts).
The server has a 2 TB SSD and I devote exactly half of it to a nginx cache for the object storage. It caches for up to a year.
PeerTube doesn't support horizontal scaling so I don't think I can use a load balancer. I don't know much about using CDNs.
Going by the server stats, that's 10% of the uploaded media, which should be pretty good I imagine (assuming a fraction of videos are popular and get a lot of requests while most videos don't get many views at all).
I guess another potential thing to look for is if people are deliberately trying to DOS the site. Not quite bringing it down, but draining resources. I could imagine some radlibs or NAFO dorks trying something like this if they caught wind of the place. Could also be caused by scrapers (a growing problem on the Fediverse and the Internet generally, driven by legions of tech bros trying to feed data to their bespoke AI models so they can be bought out by Andreesen-Horowitz).
I devote exactly half of it to a nginx cache for the object storage. It caches for up to a year.
I bet there's a ton of low hanging fruit optimizations to be done with the caching
I couldn't find Nginxs replacement policy but I'm going to assume it's LRU like 99% of everything else
Can I ask what your current caching strategy is? Like what/how things gets cached
I.e. what types of files, if any custom settings like this file needs to be requested at least 5 times before nginx caches it (default is once), etc.
I devote exactly half of it to a nginx cache for the object storage. It caches for up to a year.
I bet there's a ton of low hanging fruit optimizations to be done with the caching
I couldn't find Nginxs replacement policy but I'm going to assume it's LRU like 99% of everything else
Can I ask what your current caching strategy is? Like what/how things gets cached
I.e. what types of files, if any custom settings like this file needs to be requested at least 5 times before nginx caches it (default is once), etc.
welp you made tankietube now make a mythical compression algo tankiepress or something
What did you do??? Do you own fucking YouTube or something???
TankieTanuki owns TankieTube, which is like YouTube but better
He runs TankieTube
When I knew TankieTanuki he was just a refuse varmint, now he's a big shot webhoster.
Is this because of all the remote transcoding, or are you getting that much traffic?
Both.
When you enable "remote runners" in the PeerTube settings, the server stops transcoding entirely. In order to continue using the server CPU, it's necessary to register the local machine as a "remote" runner.
I did that last week. Now all the transcoding is run as a separate process by a dedicated Linux user,
prunner. However, when I first registered the local runner, I said "send all the finished files tohttps://tankie.tube" because that's what the docs said. That had the effect of doubling all the transcoding traffic to the server because it was sending files to itself via the public net. Very bad. so I changed it tohttp://127.0.0.1:9000.Now there is no more doubling of the traffic, but it's apparently still too much traffic. If I were to add any truly "remote" runners, it would increase the traffic even more.
Ok Vlad
Dear Tankie
Stop uploading communism or i will start to sharpen the stakes
Vlad

Vlad Alexandru

Average Ramnicu Valcea resident
real Tepes hours
Have you tried turning it off and on again?
Did you buy hosting from some person trying to do a startup in their college dorm?
Have you asked the peertube people?
How much of this is between TankieTube and end users / peer instances vs. back and forth between TankieTube and the object storage provider? I don't know how they're measuring this, but if they are combining upload and download together as "traffic," then you are getting dinged twice for every video TT proxies (download from object storage, upload to end user). If a lot of round trips are being made between TT and the object storage provider, you might be able to alleviate this somewhat with caching (requiring more local disks) on the instance. Ideally, you should cache as much video as possible on the main server granting whatever headroom is needed for postgres etc. and fetch from object storage only on a cache miss.
Alternately, depending on the object storage provider, it might be possible for end users to download the media directly from them (using HTTP redirects), but object storage usually meters bandwidth and charges for it.
If none of this is sufficient, you might need to look into load balancing / CDN. I know jack shit about this though, I just run a Mastodon instance.